Blog
IS 603 Arquitectura de Computadoras UNAH Parcial 1
Temarios, ejercicios y guías de estudio para la clase IS603 de la carrera de ingeniería en sistemas de la UNAH.

Progreso
0 de 79 tareas completadas
0%
Pagina 1 de 10
IS 603 Arquitectura de Computadoras UNAH Parcial 1
Parcial 1 - Temario y Checklist 20 dias
Ruta de estudio para rendimiento de computadoras y estructuras de interconexion. Esta version combina el temario, lecturas minimas, checklist progresivo de 20 dias y ejercicios interactivos.
Pagina 2 de 10
Fuentes principales
Fuentes principales
Presentacion: Rendimiento en las computadoras
Base principal para rendimiento, CPI, Amdahl, MIPS, promedios y SPEC.
Abrir fuentePresentacion: Estructuras de interconexion
Base principal para buses, arbitraje, temporizacion, ancho de banda y transferencias.
Abrir fuentePresentacion: Contenido sintetico y analitico
Mapa oficial de la Unidad 1 del curso.
Abrir fuenteStallings 7a edicion
Capitulos 2 y 3 para rendimiento, estructura del computador, interconexion y buses.
Abrir fuenteStallings 10th edition
Capitulos 2 y 3 como refuerzo actualizado de rendimiento e interconexion.
Abrir fuentePatterson y Hennessy 4a edicion
Capitulo 1, especialmente la seccion de prestaciones.
Abrir fuenteComputer Architecture: A Quantitative Approach
Capitulo 1 para medicion cuantitativa, medias y principios de rendimiento.
Abrir fuenteNull y Lobur
Capitulos 4, 7 y 10 para bus, E/S, Amdahl y medicion de rendimiento.
Abrir fuenteMorris Mano
Consulta opcional para organizacion basica, buses y transferencia entre registros.
Abrir fuentePagina 3 de 10
Temario del parcial
Temario del Parcial 1
| Tema | Que debes poder hacer | Donde estudiarlo |
|---|---|---|
| 1. Rendimiento basico | Tiempo de respuesta, productividad/throughput y rendimiento como inverso del tiempo de ejecucion. | Rendimiento, diap. 3-11; Patterson cap. 1.4; Stallings 10 cap. 2.4. |
| 2. Comparacion relativa | Calcular cuantas veces una maquina es mas rapida que otra y convertirlo a porcentaje. | Rendimiento, diap. 7-11; Patterson cap. 1.4. |
| 3. Reloj del procesador | Frecuencia, periodo/ciclo, unidades Hz, MHz, GHz, ns y conversiones. | Rendimiento, diap. 16-18; Estructuras, diap. 91-100. |
| 4. Ecuacion de tiempo de CPU | Tiempo CPU = ciclos x tiempo de ciclo = IC x CPI / frecuencia. | Rendimiento, diap. 19-25; Patterson cap. 1.4. |
| 5. CPI e instrucciones | CPI promedio, mezcla de instrucciones, conteo de instrucciones y decisiones de diseno. | Rendimiento, diap. 24-31 y 37-46; Stallings 10 cap. 2.4. |
| 6. Ley de Amdahl | Aceleracion parcial, fraccion mejorada, limite teorico y errores comunes al mezclar porcentajes. | Rendimiento, diap. 32-36; Stallings 10 cap. 2.3; Null/Lobur cap. 7.2. |
| 7. Metricas MIPS/MFLOPS | Que miden, cuando sirven y por que pueden enganar si se comparan ISAs o programas distintos. | Rendimiento, diap. 47-51; Stallings 10 cap. 2.4. |
| 8. Promedios y benchmarks | Media aritmetica, armonica, geometrica, SPEC y resumen de razones de rendimiento. | Rendimiento, diap. 52-61; Quantitative Approach cap. 1.8. |
| 9. Sistema Von Neumann | Modulos principales: procesador, memoria, E/S e interconexion. | Estructuras, diap. 3-13; Stallings 7 cap. 3.1-3.3. |
| 10. Lineas de bus | Bus de datos, direcciones y control; direccionabilidad y comandos/temporizacion. | Estructuras, diap. 12-24; Stallings 7 cap. 3.4. |
| 11. Capacidad direccionable | Locaciones direccionables = 2^n y papel del bus de direcciones. | Estructuras, diap. 19-23. |
| 12. Ancho de banda de bus | Bytes por transferencia, frecuencia, ciclos por transferencia y conversion de unidades. | Estructuras, diap. 17-18, 91-100 y 121-128. |
| 13. Jerarquia de buses | Backplane, bus procesador-memoria, bus de E/S, bus local, sistema, expansion y bridge. | Estructuras, diap. 34-46; Stallings 7 cap. 3.4. |
| 14. Diseno de buses | Lineas dedicadas vs multiplexadas, ventajas, costo, cantidad de lineas y rendimiento. | Estructuras, diap. 47-58 y 110-120. |
| 15. Arbitraje | Centralizado, descentralizado, daisy chain, arbitraje paralelo, polling, prioridad e imparcialidad. | Estructuras, diap. 59-77; Stallings 7 cap. 3.4. |
| 16. Temporizacion | Bus sincrono, asincrono, semisincrono, ciclos de espera y protocolo handshaking. | Estructuras, diap. 78-109. |
| 17. Tipos de transferencia | Lectura, escritura, lectura-modificacion-escritura, transferencia por bloques y operaciones combinadas. | Estructuras, diap. 110-120. |
| 18. Interconexion moderna | PCI, PCI Express, QPI, capas de enlace y diferencia entre bus compartido y punto a punto. | Estructuras, diap. 143 en adelante; Stallings 10 cap. 3. |
Pagina 4 de 10
Lecturas minimas
Lecturas minimas por tema
Las paginas son aproximadas cuando dependen de la edicion o del visor PDF. Prioriza las diapositivas marcadas como Alta y usa los libros para reforzar teoria o buscar ejercicios similares.
| Fuente | Seccion | Objetivo | Prioridad |
|---|---|---|---|
| Presentacion de rendimiento | Diap. 3-15 | Conceptos de rendimiento, productividad, tiempo de respuesta y comparaciones relativas. | Alta |
| Presentacion de rendimiento | Diap. 16-31 | Reloj, ciclos, CPI, tiempo de CPU y ejemplos de comparacion. | Alta |
| Presentacion de rendimiento | Diap. 32-46 | Ley de Amdahl, mejora parcial, mezcla de instrucciones y decisiones de diseno. | Alta |
| Presentacion de rendimiento | Diap. 47-61 | MIPS, MFLOPS, medias y benchmarks SPEC. | Media |
| Presentacion de estructuras de interconexion | Diap. 3-24 | Buses, modulos de computadora, lineas de datos, direcciones y control. | Alta |
| Presentacion de estructuras de interconexion | Diap. 34-58 | Jerarquia de buses, bridges, buses dedicados y multiplexados. | Alta |
| Presentacion de estructuras de interconexion | Diap. 59-77 | Arbitraje centralizado, descentralizado, daisy chain, paralelo y polling. | Alta |
| Presentacion de estructuras de interconexion | Diap. 78-109 | Temporizacion sincrona, asincrona, ciclos de espera y handshaking. | Alta |
| Presentacion de estructuras de interconexion | Diap. 110-128 | Tipos de transferencias y calculos de ancho de banda. | Alta |
| Presentacion de estructuras de interconexion | Diap. 129-142 | Problemas guiados de buses, memoria, wait states y comparacion sinc/asinc. | Alta |
| Stallings 7a edicion | Cap. 2, aprox. p. 17-51 | Diseno para prestaciones, balance del sistema y problemas de rendimiento. | Media |
| Stallings 7a edicion | Cap. 3, aprox. p. 57-98 | Vista de alto nivel, estructuras de interconexion, buses y problemas. | Alta |
| Stallings 10th edition | Cap. 2, aprox. p. 45-74 | Rendimiento, Amdahl, medidas basicas, medias y SPEC. | Media |
| Stallings 10th edition | Cap. 3, aprox. p. 80 en adelante | Funcionamiento e interconexion a nivel superior. | Media |
| Patterson y Hennessy 4a edicion | Cap. 1.4 y ejercicios del cap. 1 | Prestaciones, ecuacion de CPU y razonamiento cuantitativo. | Alta |
| Quantitative Approach 5th | Cap. 1.8-1.9 y ejercicios | Medicion, resumen de rendimiento, media geometrica y principios cuantitativos. | Media |
| Null y Lobur | Cap. 4.1.2, 7.2-7.4, 10 | Bus, E/S, Amdahl y medicion/analisis de rendimiento. | Baja |
| Morris Mano | Secciones de organizacion basica y buses | Refuerzo conceptual de transferencia entre registros y organizacion del computador. | Baja |
Pagina 5 de 10
Checklist dias 1 a 5
Checklist de 20 dias
Ruta actualizada para cubrir las lecturas minimas, el Banco de Ejercicios y los Apendices A-C. La idea es que cada tema tenga lectura, practica y una justificacion corta de respuesta.
Dia 1: Mapa del parcial y ruta de practica1.0 h
Dia 2: Rendimiento base y comparacion relativa1.5 h
Dia 3: Reloj, ciclos y tiempo de CPU2.0 h
Dia 4: CPI y mezcla de instrucciones2.0 h
Dia 5: Pautas de CPI y seleccion multiple2.0 h
Pagina 6 de 10
Checklist dias 6 a 10
Checklist dias 6 a 10
Dia 6: Amdahl y mejoras parciales2.0 h
Dia 7: MIPS, promedios y medicion2.0 h
Dia 8: Integracion de rendimiento2.0 h
Dia 9: Sistema Von Neumann y lineas de bus1.5 h
Dia 10: Formato de instruccion y transferencia entre registros1.75 h
Pagina 7 de 10
Checklist dias 11 a 15
Checklist dias 11 a 15
Dia 11: Ancho de banda y buses sincronicos2.0 h
Dia 12: Diseno de buses y espacios de memoria2.0 h
Dia 13: Arbitraje del bus1.5 h
Dia 14: Temporizacion, memoria lenta y wait states2.0 h
Dia 15: Transferencias, almacenamiento e interrupciones2.0 h
Pagina 8 de 10
Checklist dias 16 a 20
Checklist dias 16 a 20
Dia 16: Organizacion del procesador segun Morris Mano2.0 h
Dia 17: Practica mixta de interconexion2.0 h
Dia 18: Barrido completo del Banco de Ejercicios2.5 h
Dia 19: Simulacro con apendices2.5 h
Dia 20: Repaso final1.5 h
Pagina 9 de 10
Banco de ejercicios
Banco de Ejercicios
Hennessy y Patterson - Capitulo 1
1.2 - Fundamentos - Tamaño, red y jerarquia de memoria
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.2 - Fundamentos - Tamaño, red y jerarquia de memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.2 - Fundamentos - Tamaño, red y jerarquia de memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 1.2.1: 1280 x 800 x 3 bytes = 3,072,000 bytes.
- 1.2.2: con 2 GiB, 2 x 2^30 / 3,072,000 = 699 cuadros aprox.
- 1.2.3: 256 KiB = 2,097,152 bits; a 1 Gbit/s tarda 0.0021 s, aprox. 2.1 ms.
- 1.2.4: si cache tarda 2 us, DRAM tarda 20 us, disco 2 s y flash 2 ms.
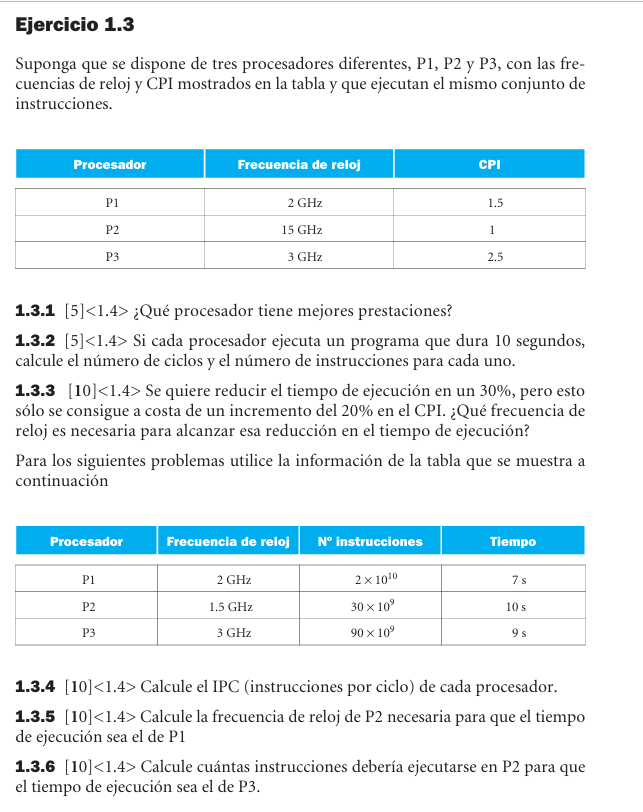
1.3 - Rendimiento - Frecuencia, CPI e instrucciones
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.3 - Rendimiento - Frecuencia, CPI e instrucciones" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.3 - Rendimiento - Frecuencia, CPI e instrucciones" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 1.3.1: rendimiento = frecuencia/CPI. P1 = 1.33, P2 = 1.50, P3 = 1.20 GIPS; gana P2.
- 1.3.2: en 10 s: P1 = 20e9 ciclos y 13.33e9 instrucciones; P2 = 15e9 ciclos y 15e9 instrucciones; P3 = 30e9 ciclos y 12e9 instrucciones.
- 1.3.3: si el tiempo baja a 0.7 y el CPI sube 20%, f nueva = (1.2/0.7)f = 1.714f.
- 1.3.4: IPC: P1 = 1.43, P2 = 2.00, P3 = 3.33.
- 1.3.5: P2 necesita 15e9 ciclos / 7 s = 2.14 GHz.
- 1.3.6: P2 en 9 s ejecuta 1.5e9 x 9 x 2 = 27e9 instrucciones.
1.4 - Rendimiento - Mezcla de instrucciones y CPI global
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.4 - Rendimiento - Mezcla de instrucciones y CPI global" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.4 - Rendimiento - Mezcla de instrucciones y CPI global" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 1.4.1: P1: CPI = 2.8, tiempo = 2.8e6/1.5e9 = 1.87 ms. P2: CPI = 2, tiempo = 1.0 ms. P2 es mas rapida.
- 1.4.2: CPI global: P1 = 2.8; P2 = 2.0.
- 1.4.3: ciclos: P1 = 2.8e6; P2 = 2.0e6.
- 1.4.4: ciclos = 500(1)+50(5)+100(5)+50(2)=1350; tiempo = 675 ns a 2 GHz.
- 1.4.5: CPI = 1350/700 = 1.93.
- 1.4.6: carga pasa de 100 a 50; ciclos nuevos = 1100, CPI nuevo = 1100/650 = 1.69 y speedup = 1350/1100 = 1.23.
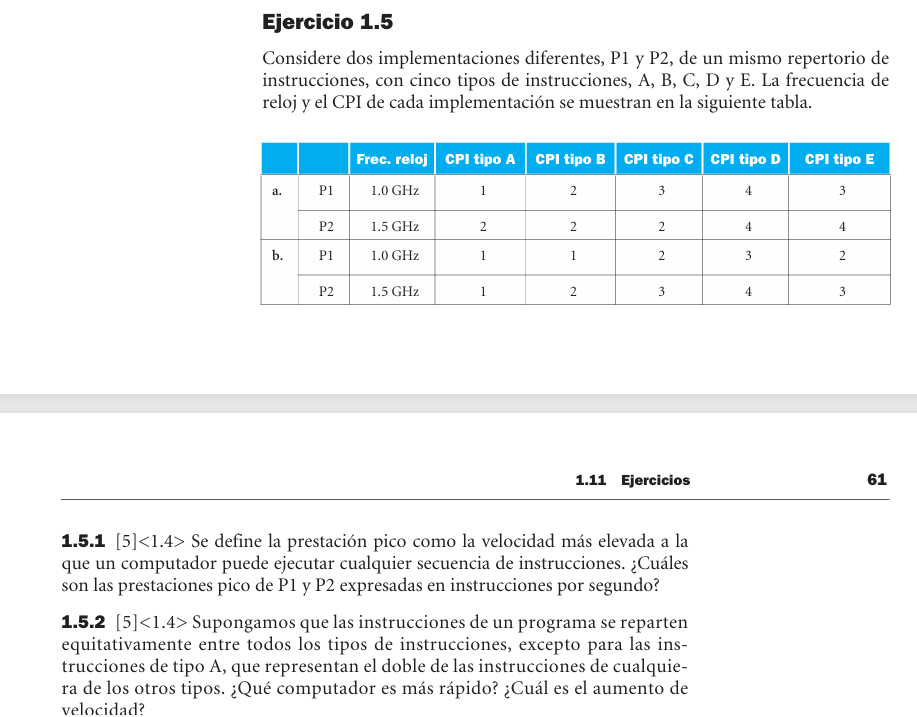
1.5 - Rendimiento - Prestacion pico, mezcla y tiempo de ejecucion
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir captura 1
Abrir captura 1 Abrir captura 2
<textarea class="answer-box" aria-label="Respuesta para 1.5 - Rendimiento - Prestacion pico, mezcla y tiempo de ejecucion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir captura 2
<textarea class="answer-box" aria-label="Respuesta para 1.5 - Rendimiento - Prestacion pico, mezcla y tiempo de ejecucion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir captura 1Abrir captura 2
- Prestacion pico: caso a: P1 = 1.0 GIPS y P2 = 0.75 GIPS. Caso b: P1 = 1.0 GIPS y P2 = 1.5 GIPS.
- Si A es doble: caso a, P2 es 1.31x mas rapida; caso b, P2 es 1.07x mas rapida.
- Si E es doble: caso a, P2 es 1.33x mas rapida; caso b, P2 es 1.03x mas rapida.
- Programas: con CPI carga/almacenamiento = 10 y salto = 3, P1 tarda 2.05 us y P2 tarda 1.93 us a 3 GHz.
- Con carga/almacenamiento = 2: P1 tarda 0.717 us y P2 tarda 0.867 us.
- Reduciendo calculo a la mitad: speedup aprox. P1 = 1.09 y P2 = 1.15.
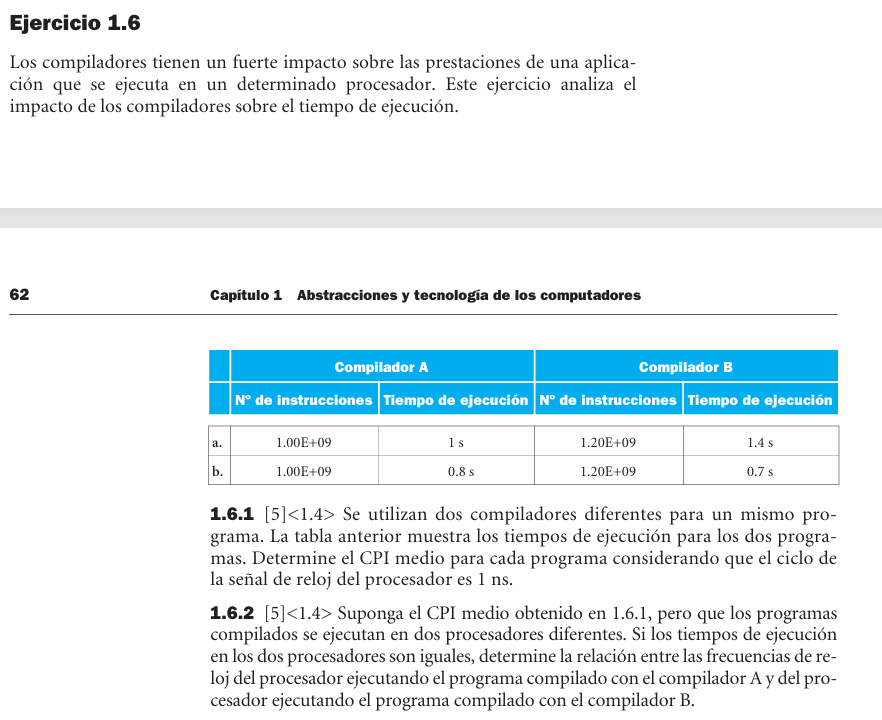
1.6 - Rendimiento - Compiladores, CPI y procesadores
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir captura 1
Abrir captura 1 Abrir captura 2
Abrir captura 2 Abrir captura 3
<textarea class="answer-box" aria-label="Respuesta para 1.6 - Rendimiento - Compiladores, CPI y procesadores" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir captura 3
<textarea class="answer-box" aria-label="Respuesta para 1.6 - Rendimiento - Compiladores, CPI y procesadores" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir captura 1Abrir captura 2Abrir captura 3
- 1.6.1: CPI = tiempo/(IC x ciclo). Caso a: A = 1.00, B = 1.17. Caso b: A = 0.80, B = 0.58.
- 1.6.2: para igual tiempo, la relacion de frecuencias sigue la relacion de ciclos. Caso a: fB = 1.4 fA. Caso b: fB = 0.875 fA.
- 1.6.3: nuevo compilador: 600M x 1.1 = 660M ciclos. Speedup caso a: contra A = 1.52, contra B = 2.12. Caso b: contra A = 1.21, contra B = 1.06.
- 1.6.4: prestaciones pico: P1 = 4 GIPS y P2 = 3 GIPS.
- 1.6.5: si A es doble, speedup P2/P1 = 1.50 en caso a y 1.22 en caso b.
- 1.6.6: frecuencia para igualar P1: caso a = 4.0 GHz; caso b = 4.92 GHz.
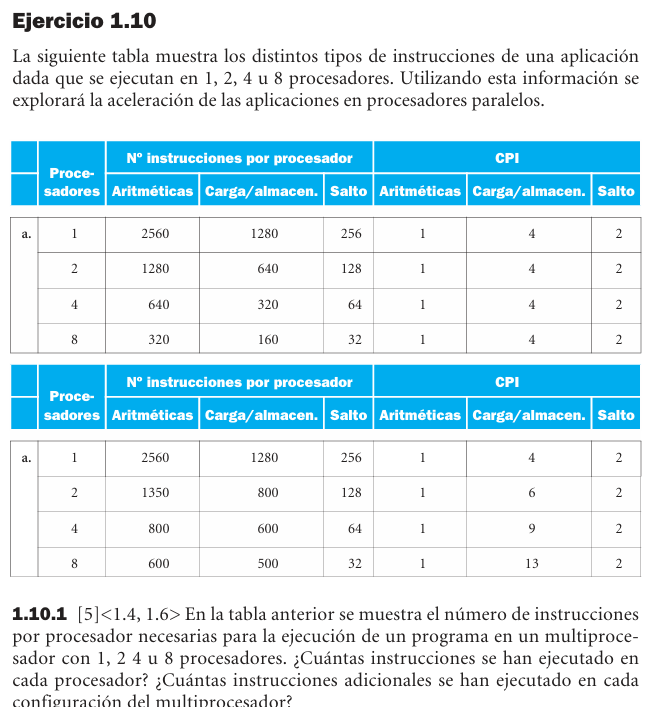
1.10 - Rendimiento - Multiprocesadores, escalamiento y energia
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir captura 1
Abrir captura 1 Abrir captura 2
Abrir captura 2 Abrir captura 3
<textarea class="answer-box" aria-label="Respuesta para 1.10 - Rendimiento - Multiprocesadores, escalamiento y energia" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir captura 3
<textarea class="answer-box" aria-label="Respuesta para 1.10 - Rendimiento - Multiprocesadores, escalamiento y energia" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir captura 1Abrir captura 2Abrir captura 3
- 1.10.1: en la tabla ideal no hay instrucciones adicionales. En la tabla no ideal: 2 proc. = 460 extra, 4 proc. = 1760 extra, 8 proc. = 4960 extra.
- 1.10.2: a 2 GHz, tabla ideal: 4.096, 2.048, 1.024 y 0.512 us. Tabla no ideal: 4.096, 3.203, 3.164 y 3.582 us.
- 1.10.3: si CPI aritmetico se duplica, tabla ideal: 5.376, 2.688, 1.344 y 0.672 us. Tabla no ideal: 5.376, 3.878, 3.564 y 3.882 us.
- 1.10.4: a 3 GHz: tabla a = 4.00, 2.17, 1.25, 0.75 s; tabla b = 4.00, 2.00, 1.00, 0.50 s.
- 1.10.5: a 3 GHz cada nucleo consume 15 W; totales: 15, 30, 60 y 120 W. A 500 MHz cada nucleo consume 0.625 W; totales: 0.625, 1.25, 2.5 y 5 W.
- 1.10.6: energia = potencia x tiempo. En tabla a a 3 GHz: 60, 65, 75 y 90 J; a 500 MHz: 15, 16.25, 18.75 y 22.5 J. En tabla b: 60 J a 3 GHz y 15 J a 500 MHz.
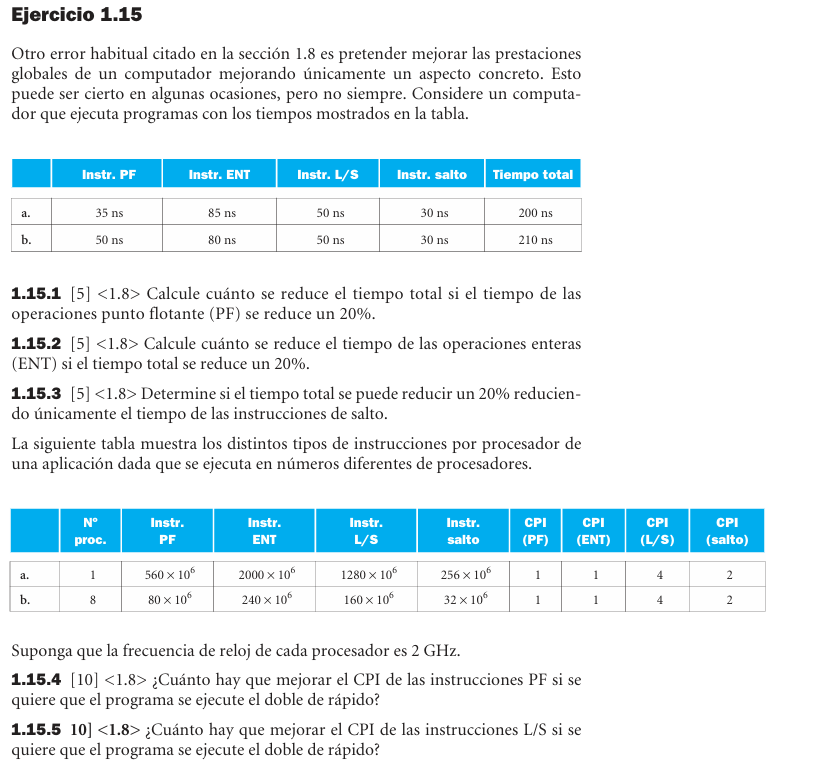
1.15 - Rendimiento - Mejoras parciales y limite de aceleracion
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.15 - Rendimiento - Mejoras parciales y limite de aceleracion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 1.15 - Rendimiento - Mejoras parciales y limite de aceleracion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 1.15.1: reducir PF 20% reduce el total a 193 ns en a y 200 ns en b.
- 1.15.2: reducir ENT 20% reduce el total a 183 ns en a y 194 ns en b.
- 1.15.3: no se puede reducir 20% solo con saltos, porque el tiempo de salto completo es menor que la reduccion requerida.
- 1.15.4: no es posible duplicar el rendimiento mejorando solo CPI de PF; los demas ciclos ya exceden el objetivo.
- 1.15.5: para duplicar, el CPI de L/S tendria que bajar a 0.8 en ambos casos.
1.16 - Rendimiento - Rutinas, comunicacion y escalamiento
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir captura 1
Abrir captura 1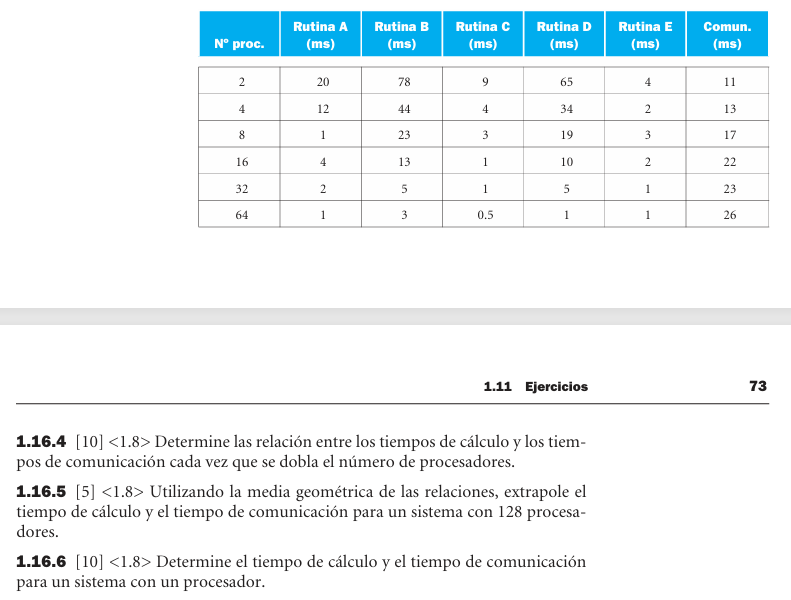 Abrir captura 2
<textarea class="answer-box" aria-label="Respuesta para 1.16 - Rendimiento - Rutinas, comunicacion y escalamiento" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir captura 2
<textarea class="answer-box" aria-label="Respuesta para 1.16 - Rendimiento - Rutinas, comunicacion y escalamiento" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir captura 1Abrir captura 2
- 1.16.1: total con 2 proc. = 185 ms; baja a 179.75 ms. Con 16 proc. = 34 ms; baja a 32.8 ms.
- 1.16.2: reducir B 10% da 177 ms con 2 proc. y 32.6 ms con 16 proc.
- 1.16.3: reducir D 10% da 178 ms con 2 proc. y 32.8 ms con 16 proc.
- 1.16.4: relacion calculo/comunicacion: 16.0, 7.38, 2.88, 1.36, 0.61 y 0.25.
- 1.16.5: usando media geometrica, para 128 proc. se estima calculo = 3.36 ms y comunicacion = 30.88 ms.
- 1.16.6: extrapolando a 1 proc.: calculo = 340.43 ms y comunicacion = 9.26 ms.
Null y Lobur - Capitulos 4, 7 y 10
4.3-4.5 - Memoria - Bits de direccionamiento
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.3-4.5 - Memoria - Bits de direccionamiento" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.3-4.5 - Memoria - Bits de direccionamiento" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 4.3: 2M x 32 = 2^21 palabras de 4 bytes. Byte-addressable: 23 bits. Word-addressable: 21 bits.
- 4.4: 4M x 16 = 2^22 palabras de 2 bytes. Byte-addressable: 23 bits. Word-addressable: 22 bits.
- 4.5: 1M x 8 = 2^20 bytes. Byte-addressable y word-addressable: 20 bits.
4.8 - Formato de instruccion - Opcode, direccion y palabra
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.8 - Formato de instruccion - Opcode, direccion y palabra" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.8 - Formato de instruccion - Opcode, direccion y palabra" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- 150 operaciones requieren ceil(log2(150)) = 8 bits para opcode.
- Quedan 24 - 8 = 16 bits para direccion.
- Memoria maxima direccionable: 2^16 palabras.
- Mayor entero sin signo en una palabra de 24 bits: 2^24 - 1 = 16,777,215.
4.9 - Memoria - Direcciones minimas y maximas
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.9 - Memoria - Direcciones minimas y maximas" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 4.9 - Memoria - Direcciones minimas y maximas" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Memoria de 2^20 bytes, byte-addressable: direcciones 0 a 2^20 - 1 = 1,048,575.
- Con palabra de 16 bits: 2 bytes por palabra, 2^19 direcciones; rango 0 a 524,287.
- Con palabra de 32 bits: 4 bytes por palabra, 2^18 direcciones; rango 0 a 262,143.
7.1 - Rendimiento - Frecuencia de reloj y comparacion real
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.1 - Rendimiento - Frecuencia de reloj y comparacion real" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.1 - Rendimiento - Frecuencia de reloj y comparacion real" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
No basta comparar 1 GHz contra 300 MHz. Si todo lo demas fuera igual, 1 GHz seria 3.33x la frecuencia, pero el rendimiento real tambien depende de CPI, numero de instrucciones, memoria, E/S y arquitectura. La respuesta correcta es advertir que la frecuencia por si sola no prueba que sea mas de tres veces mas rapida.
7.17 - Almacenamiento - Capacidad y tiempo de acceso de disco
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.17 - Almacenamiento - Capacidad y tiempo de acceso de disco" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.17 - Almacenamiento - Capacidad y tiempo de acceso de disco" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Capacidad = 4 x 1024 x 128 x 512 = 268,435,456 bytes = 256 MiB.
- Periodo rotacional = 60/5000 = 12 ms; latencia promedio = 6 ms.
- Tiempo de acceso aprox. = seek 5 ms + latencia 6 ms = 11 ms. Si se incluye transferencia de un sector: 11.094 ms.
7.18 - Almacenamiento - Comparacion de discos
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.18 - Almacenamiento - Comparacion de discos" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 7.18 - Almacenamiento - Comparacion de discos" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Capacidad = 5 x 1024 x 256 x 512 = 671,088,640 bytes = 640 MiB.
- Periodo rotacional = 60/7500 = 8 ms; latencia promedio = 4 ms.
- Tiempo de acceso aprox. = 8 + 4 = 12 ms. Con transferencia de sector: 12.031 ms.
- Comparado con 7.17, tiene mas capacidad, pero para acceso aleatorio de un sector no es mas rapido si se considera el seek dado.
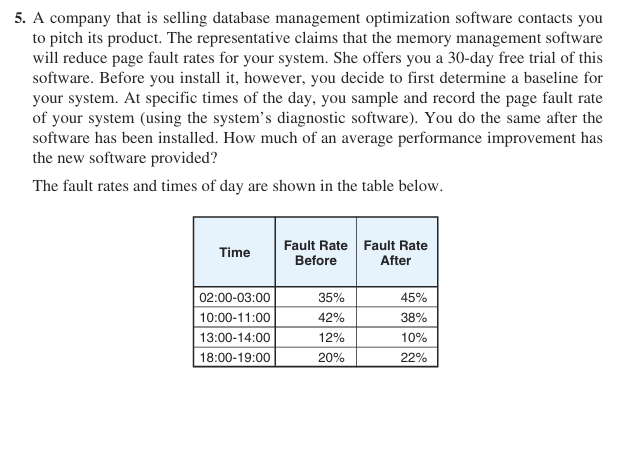
10.5 - Rendimiento - Tasa de fallos y mejora promedio
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 10.5 - Rendimiento - Tasa de fallos y mejora promedio" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 10.5 - Rendimiento - Tasa de fallos y mejora promedio" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
Promedio antes = (35 + 42 + 12 + 20)/4 = 27.25%. Promedio despues = (45 + 38 + 10 + 22)/4 = 28.75%. La tasa promedio de fallos sube 1.5 puntos porcentuales; no hay mejora promedio, sino una degradacion relativa de 1.5/27.25 = 5.5% aprox.
10.25 - Rendimiento - Ciclos promedio, MIPS y accesos a memoria
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 10.25 - Rendimiento - Ciclos promedio, MIPS y accesos a memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 10.25 - Rendimiento - Ciclos promedio, MIPS y accesos a memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Ciclos promedio = 0.175(2)+0.125(4)+0.35(8)+0.20(12)+0.15(16)=8.45 ciclos/instruccion.
- Para 1 MIPS se requieren 8.45 x 10^6 ciclos/s = 8.45 MHz.
- Si 30% de instrucciones agregan 16 ciclos por memoria, se suma 0.30 x 16 = 4.8. Nuevo promedio = 13.25 ciclos/instruccion.
Stallings 7 - Capitulos 2 y 3
2.11 - Rendimiento - MIPS, reloj y CPI
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.11 - Rendimiento - MIPS, reloj y CPI" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.11 - Rendimiento - MIPS, reloj y CPI" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
MIPS = instrucciones por segundo / 10^6. Si la frecuencia del reloj es f y el CPI es ciclos por instruccion, entonces instrucciones/s = f/CPI. Por tanto: MIPS = f / (CPI x 10^6).
2.12 - Rendimiento - MIPS, conteo de instrucciones y CPI
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.12 - Rendimiento - MIPS, conteo de instrucciones y CPI" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.12 - Rendimiento - MIPS, conteo de instrucciones y CPI" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Conteo dinamico: VAX = 1 MIPS x 12x = 12x millones; IBM = 18 MIPS x x = 18x millones. El IBM ejecuta 1.5 veces mas instrucciones.
- CPI = frecuencia/MIPS. VAX: 5 MHz/1 MIPS = 5. IBM: 25 MHz/18 MIPS = 1.39.
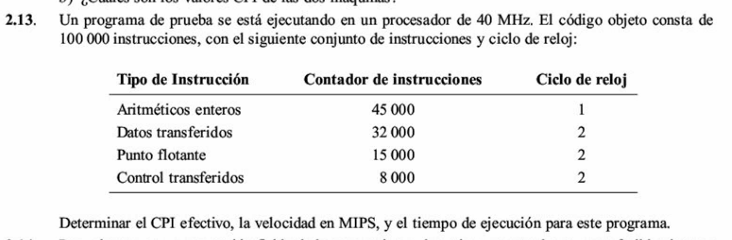
2.13 - Rendimiento - CPI efectivo, MIPS y tiempo de ejecucion
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.13 - Rendimiento - CPI efectivo, MIPS y tiempo de ejecucion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.13 - Rendimiento - CPI efectivo, MIPS y tiempo de ejecucion" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Ciclos = 45,000(1)+32,000(2)+15,000(2)+8,000(2)=155,000.
- CPI efectivo = 155,000/100,000 = 1.55.
- MIPS = 40/1.55 = 25.8 MIPS.
- Tiempo = 155,000/40e6 = 0.003875 s = 3.875 ms.
2.14 - Rendimiento - Medias aritmetica y armonica
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.14 - Rendimiento - Medias aritmetica y armonica" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 2.14 - Rendimiento - Medias aritmetica y armonica" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- La media aritmetica favorece resultados extremos; la armonica es mas adecuada cuando se promedian tasas para el mismo trabajo.
- MIPS por programa: A = 400, 0.4, 0.8, 4; B = 40, 4, 0.4, 0.5; C = 20, 20, 8, 4.
- Media aritmetica: A = 101.3, B = 11.225, C = 13.0.
- Media armonica: A = 0.999, B = 0.838, C = 8.421. Ranking por armonica: C, A, B.
3.3 - Interconexion - Formato de instruccion y buses
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.3 - Interconexion - Formato de instruccion y buses" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.3 - Interconexion - Formato de instruccion y buses" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Con instruccion de 32 bits y opcode de 8 bits, quedan 24 bits para direccion/operando.
- Capacidad directa byte-addressable: 2^24 bytes = 16 MiB.
- Un bus de datos local de 16 bits obliga a dos transferencias para una instruccion de 32 bits; uno de 32 bits reduce ese costo.
- PC necesita 24 bits si solo se direcciona ese espacio directo; IR necesita 32 bits para contener la instruccion completa.
3.4 - Interconexion - Espacios de memoria y E/S
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.4 - Interconexion - Espacios de memoria y E/S" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.4 - Interconexion - Espacios de memoria y E/S" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Con 16 bits de direccion hay 2^16 direcciones.
- Si la memoria es de 16 bits por palabra: 64K palabras = 128 KiB.
- Si la memoria es de 8 bits por palabra: 64 KiB.
- Con E/S separada y campo de puerto de 8 bits: 256 puertos de 8 bits, o 128 puertos de 16 bits si cada puerto de 16 bits ocupa dos direcciones de 8 bits.
3.5 - Interconexion - Bus externo, reloj y transferencia maxima
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.5 - Interconexion - Bus externo, reloj y transferencia maxima" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.5 - Interconexion - Bus externo, reloj y transferencia maxima" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Ciclo de bus minimo = 4 ciclos de reloj. A 8 MHz, T = 125 ns y ciclo de bus = 500 ns.
- Bus externo de 16 bits transfiere 2 bytes por ciclo de bus.
- Velocidad maxima = 2 bytes / 500 ns = 4 MB/s.
- Un bus de 32 bits o duplicar la frecuencia duplicaria el maximo teorico a 8 MB/s, asumiendo que memoria y control soporten el cambio.
3.7 - Interconexion - Bus de datos externo de 8 vs 16 bits
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.7 - Interconexion - Bus de datos externo de 8 vs 16 bits" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.7 - Interconexion - Bus de datos externo de 8 vs 16 bits" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Si instrucciones y operandos son de 1 byte, un bus de 16 bits no mejora frente a uno de 8 bits para esas transferencias: factor 1.
- Si instrucciones u operandos son de 2 bytes, el bus de 16 bits puede transferirlos en un ciclo y el de 8 bits en dos: factor 2.
3.12 - Interconexion - Temporizacion de memoria y estados de espera
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.12 - Interconexion - Temporizacion de memoria y estados de espera" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.12 - Interconexion - Temporizacion de memoria y estados de espera" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
La respuesta numerica depende de los tiempos exactos de la Figura 3.19. El procedimiento es: calcular el tiempo disponible desde que la direccion/lectura son validas hasta que el procesador muestrea datos, comparar contra 180 ns y agregar estados de espera hasta cubrir la diferencia. Formula: waits = ceil((180 ns - tiempo_disponible) / periodo_reloj). La senal Ready debe muestrearse antes del punto en que el procesador capturaria el dato; debe mantenerse baja durante todo el intervalo en que se desean insertar ciclos de espera.
3.14 - Interconexion - Instruccion de incremento y ciclos de memoria
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.14 - Interconexion - Instruccion de incremento y ciclos de memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.14 - Interconexion - Instruccion de incremento y ciclos de memoria" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- Duracion base: 4 + 3 + 3 + 3 + 3 = 16 ciclos.
- Hay cuatro accesos a memoria: opcode, direccion, operando y escritura. Dos waits por acceso agregan 8 ciclos.
- Nueva duracion = 24 ciclos; incremento = 8/16 = 50%.
- Si la operacion tarda 13 ciclos, base = 26 y nueva = 34; incremento = 8/26 = 30.8%.
3.15 - Interconexion - Temporizacion tipo 8088 y transferencia
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.15 - Interconexion - Temporizacion tipo 8088 y transferencia" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.15 - Interconexion - Temporizacion tipo 8088 y transferencia" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- El 8088 usa bus externo de 8 bits. Con 4 ciclos por lectura y 8 MHz, una transferencia de 1 byte tarda 4/8e6 = 0.5 us.
- Velocidad maxima = 1 byte / 0.5 us = 2 MB/s.
- Con un estado de espera por byte, tarda 5 ciclos: velocidad = 8 MHz / 5 = 1.6 MB/s.
3.17 - Interconexion - Mejora por procesador/bus de 32 bits
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.17 - Interconexion - Mejora por procesador/bus de 32 bits" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.17 - Interconexion - Mejora por procesador/bus de 32 bits" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
- En un bus de 16 bits, los elementos de 32 bits requieren 2 ciclos; los de 16 y 8 bits requieren 1.
- Ciclos promedio = 0.20(2)+0.40(1)+0.40(1)=1.2 ciclos.
- Con bus de 32 bits, todo cabe en 1 ciclo. Mejora = 1.2/1 = 1.2, es decir 20%.
3.18 - Interconexion - Captacion de operando e interrupciones
Intenta resolverlo sin ver la solucion. Escribe tu respuesta y procedimiento aqui.
 Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.18 - Interconexion - Captacion de operando e interrupciones" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Abrir imagen original
<textarea class="answer-box" aria-label="Respuesta para 3.18 - Interconexion - Captacion de operando e interrupciones" placeholder="Escribe aqui tu respuesta, formulas y justificacion..."></textarea>
Solucion guiada y resultado esperado.
Abrir imagen original
La interrupcion se atiende al terminar la instruccion actual. Si la linea se activa al iniciar la captacion del operando, faltan captacion del operando, operacion y almacenamiento: 3 + 3 + 3 = 9 ciclos. Con reloj de 10 MHz, T = 100 ns; tiempo = 9 x 100 ns = 900 ns.
Pagina 10 de 10
Apendices
Apendices
Apendice A: Ejercicios de la presentacion
- Rendimiento diap. 5: Identificar como cambia rendimiento cuando cambia tiempo de respuesta o productividad.
- Rendimiento diap. 10-11: Calcular razon de rendimiento y porcentaje de mejora.
- Rendimiento diap. 20-25: Aplicar tiempo CPU, ciclos, CPI y frecuencia.
- Rendimiento diap. 26-29: Comparar secuencias de codigo o maquinas con CPI distinto.
- Rendimiento diap. 32-36: Resolver Amdahl con fraccion mejorada y aceleracion parcial.
- Rendimiento diap. 37-44: Evaluar tradeoffs de diseno usando mezcla de instrucciones.
- Rendimiento diap. 47-61: Calcular MIPS/MFLOPS y medias de rendimiento.
- Estructuras diap. 18: Calcular velocidad maxima de transferencia en bus de datos.
- Estructuras diap. 20: Calcular locaciones direccionables con 2^n.
- Estructuras diap. 91-100: Resolver bus sincrono: periodo, ancho de banda, archivo, memoria lenta y multiplexacion.
- Estructuras diap. 121-128: Resolver ancho de banda de video, ISA, EISA, PCI, PCIe y bus frontal.
- Estructuras diap. 129-142: Problemas guiados 3.5, 3.7, 3.11 y 3.13 sobre buses.
Apendice B: Ejercicios de pauta Parcial 1
Pauta 1 - Problema 1 - CPI promedio por aplicacion
Problema 1 (25%). Considere las aplicaciones de compresion de datos y de simulacion de reactor nuclear. Suponga que los CPI promedio para las instrucciones de las clases A-F en dos maquinas M1 y M2 son:
| Clase | CPI promedio M1 | CPI promedio M2 | Descripcion |
|---|---|---|---|
| A | 4 | 3.8 | Load/Store |
| B | 1.5 | 2.5 | Aritmetica enteros |
| C | 1.2 | 1.2 | Shift/Logical |
| D | 6 | 2.6 | Floating-Point |
| E | 2.5 | 2.2 | Branch |
| F | 2 | 2.3 | Todas las demas |
Uso de frecuencia, en porcentaje, para dos aplicaciones:
| Clase | Compresion de datos | Simulacion de reactor nuclear |
|---|---|---|
| Load/Store | 25 | 32 |
| Aritmetica enteros | 32 | 17 |
| Shift/Logical | 16 | 2 |
| Floating-Point | 0 | 34 |
| Branch | 19 | 9 |
| Todas las demas | 8 | 6 |
- Calcule los CPI promedio para estas dos aplicaciones en cada maquina.
- Para cada aplicacion, calcule la aceleracion de M2 sobre M1, suponiendo que ambas maquinas tienen la misma tasa de reloj.
Solucion guiada y resultado esperado.
- Compresion: CPI M1 = 2.307; CPI M2 = 2.544.
- Reactor: CPI M1 = 3.944; CPI M2 = 2.885.
- Aceleracion M2/M1 = tiempo M1 / tiempo M2 = CPI M1 / CPI M2. Compresion: 0.907, por lo que M2 no acelera. Reactor: 1.367x.
Pauta 1 - Problema 2 - Concurso de algoritmos y CPI
Problema 2 (25%). Se ha realizado un concurso de algoritmos en ensamblador. El algoritmo que menor tiempo emplee y menos instrucciones ejecute sera el ganador. El codigo esta formado por tres tipos de instrucciones:
| Instruccion | CPI |
|---|---|
| Tipo 1 | 1 |
| Tipo 2 | 2 |
| Tipo 3 | 3 |
Programas finalistas:
| Programa | Tipo 1 | Tipo 2 | Tipo 3 |
|---|---|---|---|
| Programa 1 | 2 | 1 | 2 |
| Programa 2 | 4 | 1 | 1 |
- Programa que ejecuta el mayor numero de instrucciones.
- Numero de ciclos que tarda en ejecutarse cada programa.
- CPI para cada programa.
Solucion guiada y resultado esperado.
- Programa 1 ejecuta 5 instrucciones; Programa 2 ejecuta 6. El mayor numero lo ejecuta Programa 2.
- Ciclos P1 = 2(1)+1(2)+2(3)=10. Ciclos P2 = 4(1)+1(2)+1(3)=9.
- CPI P1 = 10/5 = 2. CPI P2 = 9/6 = 1.5.
Pauta 1 - Problema 3 - Fraccion de instrucciones tipo A
Problema 3 (25%). Una arquitectura tiene dos clases de instrucciones, tipo A y tipo B. Dos procesadores implementan la arquitectura: M1 con frecuencia de 300 MHz y M2 con frecuencia de 400 MHz. Los ciclos por instruccion son:
| Tipo | CPI M1 | CPI M2 |
|---|---|---|
| A | 1 | 3 |
| B | 2 | 1 |
El fabricante de M2 dice que su procesador es 4/3 mas rapido que M1 basandose en los tiempos obtenidos en un benchmark. Determine la fraccion, en porcentaje, de instrucciones tipo A que usa dicho benchmark.
Solucion guiada y resultado esperado.
Sea x la fraccion de instrucciones A. CPI M1 = x(1)+(1-x)2 = 2-x. CPI M2 = 3x+(1-x)1 = 1+2x. Como M2 es 4/3 mas rapido, T2 = 3/4 T1. Con ciclos de reloj de 1/300 MHz y 1/400 MHz: 2.5(1+2x)=2.5(2-x), por tanto x=1/3. La fraccion de instrucciones tipo A es 33.3%.
Pauta 1 - Problema 4 - Bus sincrono y ancho de banda
Problema 4 (25%). Dentro de la jerarquia de buses de un computador, el bus de memoria esta configurado como un bus sincrono con frecuencia de reloj de 100 MHz y utiliza 4 ciclos de reloj para realizar una lectura de memoria.
- Si el ancho de banda obtenido es de 100 MB/s, ¿cual es la anchura del bus de datos?
- ¿Cuanto tiempo es necesario para transferir 5 MB por el bus y cuantos ciclos de bus necesita?
Solucion guiada y resultado esperado.
- Periodo = 1/100 MHz = 10 ns. Una lectura tarda 4 ciclos = 40 ns. Datos por lectura = 100 MB/s x 40 ns = 4 bytes = 32 bits. La anchura del bus es 32 bits.
- Tiempo = 5 MB / 100 MB/s = 0.05 s. Con 4 bytes por transferencia: 5,000,000/4 = 1,250,000 ciclos de bus. Equivale a 5,000,000 ciclos de reloj.
Apendice C: Morris Mano - Ejercicios relacionados
Practica tomada como guia de los problemas y secciones de Morris Mano sobre transferencia entre registros, buses, memoria y organizacion del procesador. Cuando un ejercicio menciona una figura, abre el PDF para ver el diagrama original.
Mano 8-1 - Transferencia entre registros - Intercambio simultaneo
Enunciado. Con la funcion de control xT3 activa, se quiere ejecutar en el mismo pulso de reloj: A <- B y B <- A. Describe el diagrama de bloque necesario para lograr el intercambio.
Solucion guiada y resultado esperado.
- La transferencia es simultanea: A debe recibir el valor viejo de B y B debe recibir el valor viejo de A.
- Conecta las salidas de B hacia las entradas de A y las salidas de A hacia las entradas de B.
- La senal
xT3habilita las cargas de ambos registros durante el mismo pulso de reloj. - Si solo existe un bus comun de una fuente a un destino, no basta para intercambiar en un solo ciclo; se requeriria un registro temporal o dos caminos de datos.
Mano 8-3 - Registros - Funcion de desplazamiento
Enunciado. Un registro de 8 bits recibe una entrada serial x. La operacion se define como P: A8 <- x, Ai <- A(i+1) para i = 1, 2, ..., 7. Las celdas se numeran de derecha a izquierda. Identifica la funcion del registro.
Solucion guiada y resultado esperado.
- Como las celdas se numeran de derecha a izquierda,
A8es el bit mas a la izquierda. A8 <- xcarga el nuevo bit serial por la izquierda.Ai <- A(i+1)mueve cada bit una posicion hacia la derecha: A8 pasa a A7, A7 pasa a A6, y asi sucesivamente.- Por tanto, la funcion es un desplazamiento a la derecha con entrada serial
xpor el bit mas significativo; el bit A1 sale o se descarta.
Mano 8-5 - Bus comun - Seleccion de fuente y destino
Enunciado. En el sistema de bus de cuatro registros, las variables se leen como s1 s0 d1 d0 e. Determina las transferencias para 00010, 01000, 11100 y 01101. Luego da los valores de seleccion para A <- B, B <- C y D <- A.
Solucion guiada y resultado esperado.
00010: fuente A, destino B, decodificador habilitado; transferenciaB <- A.01000: fuente B, destino A, decodificador habilitado; transferenciaA <- B.11100: fuente D, destino C, decodificador habilitado; transferenciaC <- D.01101: fuente B y destino C, peroe=1; no ocurre transferencia porque el decodificador no esta habilitado.- Para
A <- B:01000. ParaB <- C:10010. ParaD <- A:00110.
Mano 9-2 - Organizacion del procesador - Lineas de seleccion
Enunciado. Un procesador organizado con buses como en la Fig. 9-1 contiene 15 registros. Determina cuantas lineas de seleccion necesita cada multiplexor y cuantas necesita el decodificador de destino.
Solucion guiada y resultado esperado.
- Para seleccionar entre 15 registros se requieren
ceil(log2(15)) = 4lineas de seleccion. - Cada multiplexor necesita 4 lineas de seleccion porque debe escoger una de 15 fuentes posibles.
- El decodificador de destino tambien necesita 4 lineas de entrada para generar hasta 16 salidas; una combinacion queda sin uso o se reserva.
Mano 9-4 - Memoria scratchpad - Tamano y buses
Enunciado. Una unidad procesadora usa memoria scratchpad con 64 registros de 8 bits. Calcula: tamano total de la memoria, lineas de direccion, lineas de datos de entrada y tamano del multiplexor que selecciona entre datos externos y salida del registro de desplazamiento.
Solucion guiada y resultado esperado.
- Capacidad:
64 x 8 = 512bits, equivalentes a64bytes. - Lineas de direccion:
log2(64) = 6. - Lineas de datos de entrada: 8, porque cada registro tiene 8 bits.
- El multiplexor elige entre dos fuentes de 8 bits, asi que es un MUX 2 a 1 de 8 bits, o bien ocho multiplexores 2 a 1 de 1 bit.
Mano 11-19 - Registros del computador - CI de 4 bits
Enunciado. Si se dispone de un contador de 4 bits con carga en paralelo encapsulado como circuito integrado, determina cuantos CI se necesitan para construir los registros PC, MAR, I y G.
Solucion guiada y resultado esperado.
PCtiene 12 bits:12/4 = 3CI.MARtiene 12 bits:12/4 = 3CI.Itiene 4 bits:1CI.Gtiene 2 bits: necesita1CI, aunque solo se usen dos de sus cuatro bits.- Total:
3 + 3 + 1 + 1 = 8CI.
Comentarios
Comparte una idea, pregunta o aporte sobre este articulo.
Todavia no hay comentarios. Puedes abrir la conversacion.