Blog
IS 603 Arquitectura de Computadoras UNAH Parcial 2
Temarios, ejercicios y guías de estudio para la clase IS603 de la carrera de ingeniería en sistemas de la UNAH.

Progreso
0 de 112 tareas completadas
0%
Pagina 1 de 8
IS 603 Arquitectura de Computadoras UNAH Parcial 2
Parcial 2 - Temario y Checklist 15 dias
Temario del segundo parcial, lecturas, formulas, plan de 15 dias y bancos de ejercicios con soluciones.
Uso de los botones: la validacion automatica queda solo en ejercicios de libros con solucion revisada. Las practicas adicionales siguen enlazadas a capturas/recortes, pero no tienen boton de solucion si no deje una respuesta completa verificada.
Fuentes principales
Presentacion del segundo parcial
Stallings 7a: capitulo 4.
Patterson/Hennessy 4a: capitulo 5.
Null/Lobur: capitulo 6.
Refuerzo Morris Mano
Ir al Apendice C para leer memoria principal, MAR/MBR, RTL, formatos de instruccion y direccionamiento.
Minimo vital
Si un bloque se alarga demasiado, no te quedes pegado: marca la duda, mira la solucion o teoria, y pasa al siguiente tipo. El examen de seleccion multiple con justificacion premia reconocer el metodo correcto.
Checklist de errores
En cada ejercicio fallado anota: formula usada, campo confundido, unidad mal convertida, o si era direccion de byte/bloque. Ese mini registro vale mas que repetir sin diagnostico.
Pagina 2 de 8
Temario y banco por tema
Temario y ejercicios - Parcial 2
Mapa del parcial y banco de ejercicios por tema.
Mapa completo del parcial
| Tema | Diapositivas | Que debes saber justificar | Prioridad |
|---|---|---|---|
| Caracteristicas de sistemas de memoria | 2-4, 11 | Ubicacion, capacidad, unidad de transferencia, metodo de acceso, tecnologia, volatilidad, costo por bit, tiempo de acceso y compromiso costo-capacidad-velocidad. | Alta |
| Jerarquia de memoria | 4, 10-13 | Al bajar en la jerarquia aumenta capacidad y baja costo por bit, pero sube tiempo de acceso. Relacionar registros, L1/L2/L3, memoria principal, disco. | Alta |
| Acierto, fallo, tasa de acierto y tasa de fallo | 5-6, 10 | Diferenciar hit/miss, calcular miss rate = 1 - hit rate, explicar tiempo de acierto y penalizacion por fallo. |
Alta |
| Tiempo promedio de acceso y AMAT | 7-16, 177-188 | Aplicar formulas de dos y tres niveles; convertir unidades; calcular CPI con paradas de memoria; comparar cache perfecta contra cache real. | Alta |
| Principio de localidad | 17-18, 141-144 | Explicar localidad temporal y espacial, y como justifican traer bloques completos a cache. | Alta |
| Estructura memoria principal/cache y lectura de cache | 19-23, 40 | Bloque de memoria principal, linea de cache, etiqueta, bit de validez, datos, comparacion de tags y secuencia de lectura. | Alta |
| Cache logica y cache fisica | 24-27 | Diferenciar cache antes/despues de traduccion de direcciones: rapidez contra problemas de sinonimos/procesos. | Media |
| Funcion de asignacion y tecnicas de mapeo | 28-30 | Saber que la funcion de asignacion decide donde puede ubicarse un bloque de memoria principal dentro de la cache. | Alta |
| Asignacion directa | 31-70 | Calcular linea = bloque mod numero_de_lineas, dividir direccion en etiqueta/linea/palabra o byte, distinguir direccion de byte y direccion de bloque. |
Alta |
| Asignacion asociativa | 71-78 | Un bloque puede ir en cualquier linea; direccion se divide en etiqueta y palabra; requiere comparacion asociativa. | Media |
| Asignacion asociativa por conjuntos | 79-98, 113-128 | Calcular conjuntos, vias, formato etiqueta/conjunto/palabra; interpretar direcciones hexadecimales; ubicar una direccion dentro de un conjunto. | Alta |
| Bits de direccion, etiqueta, indice y desplazamiento | 45-56, 83-90, 91-128 | Usar log2 para numero de lineas, conjuntos, bloques y bytes por bloque; calcular bits totales de cache incluyendo etiqueta y validez. |
Alta |
| Politicas de reemplazo | 129-140 | Simular LRU con contadores o historial; reconocer LFU, FIFO y random; calcular aciertos/fallos en una secuencia de bloques. | Alta |
| Tamano de bloque/linea y tipos de fallos | 141-149 | Relacionar tamano de bloque con localidad espacial, penalizacion por fallo y tasa de fallo; reconocer fallos de lectura, instrucciones y datos. | Media |
| Politicas de escritura | 150-169 | Diferenciar escritura inmediata/write-through, escritura diferida/write-back, bit dirty, buffer de escritura, write allocate y no-write allocate. | Alta |
| Cache separada, bus, ancho de memoria e interleaving | 170-176 | Explicar cache de instrucciones/datos separada, penalizacion por fallo, memoria mas ancha y bancos entrelazados. | Media |
| Evaluacion y mejora de prestaciones de cache | 177-188 | Calcular ciclos de parada por memoria, CPI efectivo, speedup por cache perfecta, impacto de subir frecuencia sin mejorar memoria y cache multinivel. | Alta |
Banco de ejercicios por tema
| Tema | Ejercicios recomendados | Que practicar |
|---|---|---|
| Jerarquia, costo, capacidad y localidad | Stallings 7a: preguntas 4.1-4.3, 4.8-4.9; problemas 4.15-4.16. Null/Lobur: preguntas 4-8. Patterson: 5.1, 5.2. | Justificar por que existe jerarquia, diferenciar localidad temporal/espacial y reconocerla en codigo. |
| Hit/miss, tasa de acierto y tiempo promedio | Presentacion: diap. 7-16, 67-70, 180-188. Stallings 7a: problemas 4.19-4.27. Null/Lobur: preguntas 19-20 y ejercicio 10. Patterson: 5.7, 5.8.4-5.8.6. | AMAT, conversion de unidades, CPI con ciclos de parada, speedup con cache perfecta y cache multinivel. |
| Estructura de cache, tags y bit de validez | Stallings 7a: preguntas 4.5-4.7; problemas 4.4, 4.5, 4.6, 4.10, 4.11, 4.12. Null/Lobur: preguntas 10, 15. Patterson: 5.4. | Identificar etiqueta, indice/linea/conjunto, palabra/byte y calcular bits de control. |
| Asignacion directa | Presentacion: diap. 31-70, 122-125. Stallings 7a: problemas 4.3, 4.4a, 4.8, 4.11a, 4.12a-b, 4.18a, 4.28-4.29. Null/Lobur: ejercicios 1, 2, 9, 10, 11a. Patterson: 5.3, 5.4. | Modulo, formato de direccion, tabla de hits/misses, conflicto de bloques y calculo de penalizacion. |
| Asignacion totalmente asociativa | Stallings 7a: problemas 4.4b, 4.11b, 4.12c. Null/Lobur: ejercicios 3, 4, 11b. Patterson: 5.8.2, 5.8.3. | Formato etiqueta + desplazamiento, comparacion con todas las lineas y necesidad de reemplazo. |
| Asignacion asociativa por conjuntos | Presentacion: problemas 4.1, 4.2, 4.5, 4.6, 4.10. Stallings 7a: problemas 4.1, 4.2, 4.5, 4.6, 4.10, 4.11c, 4.12d, 4.17, 4.18b. Null/Lobur: ejercicios 5, 6, 7, 8, 11c. Patterson: 5.8.1. | Calcular vias, conjuntos, bits de conjunto y etiqueta; simular reemplazo dentro del conjunto. |
| Politicas de reemplazo | Presentacion: diap. 129-140. Stallings 7a: problemas 4.9, 4.13, 4.17, 4.18, 4.19. Null/Lobur: preguntas 16-18 y ejercicios 6, 9, 10. Patterson: 5.12. | LRU con contadores, FIFO, LFU, random, hits/misses por secuencia y peor caso de thrashing. |
| Tamano de bloque y tipos de fallos | Presentacion: diap. 141-149. Stallings 7a: problemas 4.14, 4.28, 4.29. Patterson: 5.6. Quantitative Approach: 2.1-2.3. | Compulsory/capacity/conflict misses, bloques grandes, comienzo inmediato, palabra critica y penalizacion promedio. |
| Politicas de escritura | Presentacion: diap. 150-169. Stallings 7a: problema 4.26. Null/Lobur: preguntas 22-23. Patterson: 5.5, 5.15. Quantitative Approach: seccion de write buffers y ejercicios 2.8-2.9. | Write-through, write-back, dirty bit, write buffer, reserva/sin reserva de escritura y fallos de escritura. |
| Cache separada, ancho de memoria e interleaving | Presentacion: diap. 170-176. Stallings 7a: seccion numero de caches y apendice 4A. Patterson: 5.5-5.8. Quantitative Approach: secciones 2.2-2.3. | Cache unificada vs separada, bus, memoria mas ancha, bancos, transferencias en rafaga y reduccion de penalizacion por fallo. |
| Prestaciones de cache y caches multinivel | Presentacion: diap. 177-188. Stallings 7a: problemas 4.20-4.27. Patterson: 5.7, 5.8.4-5.8.6. Quantitative Approach: 2.1-2.9. | AMAT multinivel, CPI total, ciclos de parada por instruccion, speedup y tradeoff tamano/latencia/asociatividad. |
Nota: las paginas indicadas son paginas del PDF para ubicarlas rapido en el visor. Cuando se indica "libro p.", corresponde a la numeracion impresa visible en la pagina.
Pagina 3 de 8
Plan de 15 dias
Dia 1
Jerarquia de memoria, localidad y vocabulario base.
Panorama del tema
Hoja base
Dia 2
Primer contacto con etiqueta, indice/bloque y desplazamiento.
Cache directa
Formatos simples
Errores tipicos
Dia 3
Calculo de lineas, entradas, etiquetas y razon de aciertos.
Direct mapping en otro enfoque
Campos y tamano de cache
Justificacion breve
Dia 4
Secuencias de referencias, aciertos, fallos y reemplazos.
Trazas de cache
Tabla de seguimiento
Dia 5
Sin indice fijo: etiqueta, palabra y ubicacion libre.
Asociativa total
Ubicacion libre
Diferencia clave
Pagina 4 de 8
Dias 6 a 10
Dia 6
Conjuntos, vias y formatos de direccion.
Set associative
Vias y conjuntos
Formula rapida
Dia 7
Dia de consolidacion antes de pasar a reemplazo y rendimiento.
Mezcla de mapeos
Resumen comparativo
Dia 8
Localidad temporal/espacial y rendimiento promedio.
Localidad y AMAT
Localidad aplicada
Mini diagnostico
Dia 9
LRU, MRU, aleatorio y estrategia optima.
Reemplazo
LRU/MRU
Regla mental
Dia 10
Write-through, write-back, write allocate y no write allocate.
Escritura y buffers
Trafico de escritura
Comparacion
Pagina 5 de 8
Dias 11 a 15
Dia 11
Bloques grandes, bus, rafagas y tasa de fallos.
Optimizaciones
Penalizacion de fallo
Idea clave
Dia 12
AMAT con L1/L2, costo promedio y cambios de diseno.
Multinivel
AMAT y costo
Formulas
Dia 13
Convertir tasas de fallo en tiempo por instruccion.
Rendimiento cuantitativo
CPI con memoria
Unidades
Dia 14
Practica acumulada sin mirar soluciones al inicio.
Ejercicios mezclados
Correccion activa
Dia 15
Cerrar huecos y dejar una hoja de examen limpia.
Hoja de formulas
Ultimos intentos
Estrategia de examen
Lista maestra de ejercicios agregados
| Fuente | Ejercicios con captura, intento y solucion |
|---|---|
| Banco principal | 4.1, 4.2, 4.3, 4.5, 4.6, 4.7, 4.8, 4.10, 4.12, 4.15, 4.17, 4.18, 4.20, 4.21, 4.22, 4.24, 4.25, 4.26, 4.27, 4.28, 4.29. |
| Patterson/Hennessy | 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.12. |
| Null/Lobur | 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. |
Pagina 6 de 8
Ejercicios con soluciones
Ejercicios de libros - Checklist con soluciones
Practica organizada por tema con capturas, espacio de intento y solucion de referencia.
Banco principal
Intentar resolver - Stallings 7a ejercicio 4.1
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.1
- Lineas de cache = 64. Como cada conjunto tiene 4 lineas, hay 64/4 = 16 conjuntos.
- 16 conjuntos requieren log2(16) = 4 bits para el campo conjunto.
- La memoria principal tiene 4K bloques = 2^12 bloques.
- Cada bloque tiene 128 palabras = 2^7, asi que el desplazamiento de palabra ocupa 7 bits.
- Etiqueta = 12 - 4 = 8 bits.
Respuesta: Formato: etiqueta = 8 bits, conjunto = 4 bits, palabra = 7 bits.
Intentar resolver - Stallings 7a ejercicio 4.2
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.2
- La memoria principal es de 64 MB direccionable por bytes: 64 MB = 2^26 bytes, por tanto la direccion tiene 26 bits.
- La linea tiene 16 bytes = 2^4, asi que el desplazamiento ocupa 4 bits.
- La cache tiene 8 KB = 8192 bytes; con lineas de 16 bytes hay 8192/16 = 512 lineas.
- Al ser de dos vias, hay 512/2 = 256 conjuntos = 2^8 conjuntos.
- Etiqueta = 26 - 8 - 4 = 14 bits.
Respuesta: Formato: etiqueta = 14 bits, conjunto = 8 bits, desplazamiento de byte = 4 bits.
Intentar resolver - Stallings 7a ejercicio 4.3
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.3
- Para correspondencia directa de la figura 4.8 se usa: etiqueta 14 bits, linea 8 bits, palabra 2 bits.
- 111111 -> etiqueta 444, linea 44, palabra 1. 666666 -> etiqueta 1999, linea 99, palabra 2. BBBBBB -> etiqueta 2EEE, linea EE, palabra 3.
- Para cache asociativa de la figura 4.10 se usa: etiqueta 22 bits y palabra 2 bits.
- 111111 -> etiqueta 44444, palabra 1. 666666 -> etiqueta 199999, palabra 2. BBBBBB -> etiqueta 2EEEEE, palabra 3.
- Para cache asociativa por conjuntos de dos vias de la figura 4.12 se usa: etiqueta 15 bits, conjunto 7 bits, palabra 2 bits.
- 111111 -> etiqueta 888, conjunto 44, palabra 1. 666666 -> etiqueta 3333, conjunto 19, palabra 2. BBBBBB -> etiqueta 5DDD, conjunto 6E, palabra 3.
Respuesta: Directa: (444,44,1), (1999,99,2), (2EEE,EE,3). Asociativa: (44444,1), (199999,2), (2EEEEE,3). Por conjuntos: (888,44,1), (3333,19,2), (5DDD,6E,3).
Intentar resolver - Stallings 7a ejercicio 4.5
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.5
- La cache tiene 16 KB y lineas de 4 palabras de 32 bits: cada linea mide 4 x 4 = 16 bytes.
- Numero de lineas = 16 KB / 16 bytes = 1024 lineas.
- Como es de cuatro vias, conjuntos = 1024/4 = 256 conjuntos, asi que el campo conjunto ocupa 8 bits.
- El desplazamiento dentro de linea ocupa log2(16) = 4 bits.
- La direccion es de 32 bits; etiqueta = 32 - 8 - 4 = 20 bits.
- Separando ABCDE8F8: etiqueta = ABCDE, conjunto = 8F, desplazamiento = 8.
- El desplazamiento 8 apunta a la tercera palabra de la linea si numeras las palabras 0,1,2,3.
Respuesta: Formato: etiqueta 20 bits, conjunto 8 bits, desplazamiento 4 bits. ABCDE8F8 -> tag ABCDE, set 8F, offset 8.
Intentar resolver - Stallings 7a ejercicio 4.6
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.6
- Cada linea tiene dos palabras de 16 bits, es decir 32 bits = 4 bytes.
- La cache almacena 4K palabras de 32 bits: 4096 x 4 bytes = 16 KB.
- Numero de lineas = 16 KB / 4 bytes = 4096 lineas.
- Al ser de cuatro vias, conjuntos = 4096/4 = 1024 conjuntos, por tanto el campo conjunto ocupa 10 bits.
- Si las direcciones de 24 bits son a byte, el desplazamiento de linea es log2(4) = 2 bits.
- Etiqueta = 24 - 10 - 2 = 12 bits.
Respuesta: Formato usual byte-addressable: etiqueta = 12 bits, conjunto = 10 bits, desplazamiento = 2 bits. Cache: 4096 lineas, 1024 conjuntos, 4 vias.
Intentar resolver - Stallings 7a ejercicio 4.7
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.7
- La cache tiene 8 KB, cuatro vias y bloques de 4 palabras de 32 bits.
- Cada bloque mide 4 x 4 = 16 bytes, asi que el desplazamiento ocupa 4 bits.
- El enunciado indica 128 conjuntos, por tanto el campo conjunto ocupa log2(128) = 7 bits.
- Con direcciones de 32 bits, etiqueta = 32 - 7 - 4 = 21 bits.
- Cada conjunto tiene cuatro lineas; cada linea contiene etiqueta, bit valido y los 16 bytes del bloque. Los bits B0, B1 y B2 sirven para pseudo-LRU.
Respuesta: Formato: etiqueta = 21 bits, conjunto = 7 bits, desplazamiento = 4 bits. Organizacion: 128 conjuntos, 4 vias, 16 bytes por linea.
Intentar resolver - Stallings 7a ejercicio 4.8
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.8
- La direccion tiene 16 bits porque la memoria tiene 2^16 bytes.
- El bloque tiene 8 bytes = 2^3, por tanto el campo byte ocupa 3 bits.
- La cache tiene 32 lineas = 2^5, por tanto el campo linea ocupa 5 bits.
- Etiqueta = 16 - 5 - 3 = 8 bits.
- Lineas: 0001 0001 0001 1011 -> 3; 1100 0011 0011 0100 -> 6; 1101 0000 0001 1101 -> 3; 1010 1010 1010 1010 -> 21.
- La direccion 0001 1010 0001 1010 pertenece al bloque que inicia en 0x1A18, asi que se cargan los bytes 0x1A18 a 0x1A1F.
- La cache almacena 32 x 8 = 256 bytes. Las etiquetas se guardan para distinguir bloques de memoria que caen en la misma linea.
Respuesta: a) etiqueta 8, linea 5, byte 3. b) lineas 3, 6, 3 y 21. c) 0x1A18-0x1A1F. d) 256 bytes. e) la etiqueta identifica que bloque esta en la linea.
Intentar resolver - Stallings 7a ejercicio 4.10
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.10
- El bloque tiene cuatro palabras de 16 bits; usando palabra de 16 bits como unidad direccionable, el desplazamiento ocupa log2(4) = 2 bits.
- La cache almacena 4096 palabras; lineas = 4096/4 = 1024 lineas.
- El tamano de conjunto es 2, asi que hay 1024/2 = 512 conjuntos = 2^9.
- La memoria principal es 64K x 32 bits, equivalente a 128K palabras de 16 bits = 2^17 palabras de 16 bits.
- Etiqueta = 17 - 9 - 2 = 6 bits.
- Si se expresa como direccion a byte, se agrega un bit de byte al desplazamiento: offset total de 3 bits, pero se conserva etiqueta 6 y conjunto 9.
Respuesta: Por palabras de 16 bits: etiqueta = 6 bits, conjunto = 9 bits, palabra = 2 bits. Cache: 1024 lineas, 512 conjuntos, 2 vias.
Intentar resolver - Stallings 7a ejercicio 4.12
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.12
- Memoria principal: 1 MB = 2^20 bytes. Bloque: 16 bytes = 2^4, por tanto desplazamiento = 4 bits.
- Cache: 64 KB = 2^16 bytes. Lineas = 2^16 / 2^4 = 2^12, asi que en directa la linea ocupa 12 bits y la etiqueta 4 bits.
- Directa: F0010 -> tag F, linea 001, offset 0. 01234 -> tag 0, linea 123, offset 4. CABBE -> tag C, linea ABB, offset E.
- Dos direcciones con misma linea y etiquetas diferentes: 00010 y F0010, ambas van a linea 001 con offset 0.
- Totalmente asociativa: F0010 -> tag F001, offset 0. CABBE -> tag CABB, offset E.
- Asociativa por conjuntos de dos vias: hay 2048 conjuntos = 2^11, por tanto tag = 20 - 11 - 4 = 5 bits.
- Dos vias: F0010 -> tag 1E, conjunto 001, offset 0. CABBE -> tag 19, conjunto 2BB, offset E.
Respuesta: Directa: F0010=(F,001,0), 01234=(0,123,4), CABBE=(C,ABB,E). Asociativa: F0010=(F001,0), CABBE=(CABB,E). 2 vias: F0010=(1E,001,0), CABBE=(19,2BB,E).
Localidad, reemplazo y tasa de aciertos
Intentar resolver - Stallings 7a ejercicio 4.15
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.15
- Localidad espacial: el arreglo a se almacena contiguamente; al avanzar i se accede a a[0], a[1], a[2], etc., que suelen estar cerca en memoria.
- Localidad temporal: para un mismo i, el elemento a[i] se reutiliza durante las 10 iteraciones del ciclo interno con j.
- Tambien hay localidad temporal en las instrucciones del ciclo, porque las mismas instrucciones se ejecutan repetidamente.
Respuesta: Espacial: accesos a elementos contiguos del arreglo a. Temporal: reutilizacion repetida de a[i] e instrucciones dentro del ciclo interno.
Intentar resolver - Stallings 7a ejercicio 4.17
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.17
- Cada linea tiene 64 palabras. La secuencia 0..4351 cubre 4352/64 = 68 bloques.
- La cache tiene 4K palabras / 64 palabras por linea = 64 lineas. Con cuatro vias hay 16 conjuntos.
- Los bloques 0..67 se reparten entre 16 conjuntos. Los conjuntos 0,1,2,3 reciben 5 bloques cada uno; los demas reciben 4.
- Primera pasada: 68 fallos, uno por bloque.
- En las siguientes 9 pasadas, los conjuntos con 5 bloques sufren conflicto; hay 20 fallos por pasada.
- Fallos totales = 68 + 9 x 20 = 248. Accesos totales = 10 x 4352 = 43520.
- Tasa de aciertos = (43520 - 248)/43520 = 0.9943 aproximadamente.
- Si memoria principal tarda 10 unidades y cache 1 unidad, tiempo medio con cache = H x 1 + (1-H) x 10 = 1.0513 unidades.
Respuesta: Fallos totales 248, tasa de aciertos aprox. 99.43%, mejora aprox. 10/1.0513 = 9.51 veces.
Intentar resolver - Stallings 7a ejercicio 4.18
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.18
- La secuencia total tiene 8 accesos iniciales mas 10 x (18 + 16) accesos del bucle = 348 accesos.
- Los bloques son de 16 bytes. La secuencia inicial 63..70 toca los bloques 3 y 4.
- En cada iteracion del bucle, 15..32 toca bloques 0,1,2 y 80..95 toca bloque 5.
- Simulando correspondencia directa de cuatro lineas, hay 24 fallos y 324 aciertos.
- Tasa directa = 324/348 = 0.9310, aproximadamente 93.1%.
- Simulando cache asociativa por conjuntos de dos vias con LRU, hay 6 fallos y 342 aciertos.
- Tasa por conjuntos = 342/348 = 0.9828, aproximadamente 98.3%.
Respuesta: Directa: 324 aciertos, 24 fallos, hit ratio 93.1%. Asociativa por conjuntos 2 vias LRU: 342 aciertos, 6 fallos, hit ratio 98.3%.
Rendimiento, AMAT y penalizacion
Intentar resolver - Stallings 7a ejercicio 4.20
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.20
- 1 MB = 2^20 bytes = 8,388,608 bits.
- Costo con tecnologia de memoria principal: 8,388,608 x 10^-5 = 83.88608 dolares.
- Costo usando tecnologia de cache: 8,388,608 x 10^-4 = 838.8608 dolares.
- El tiempo efectivo debe ser 10% mayor que el tiempo de cache: 100 ns x 1.10 = 110 ns.
- Usa Ta = Tc + (1-H)Tm: 110 = 100 + (1-H)1200.
- 1-H = 10/1200 = 0.008333; H = 0.991667.
Respuesta: a) $83.89 aprox. b) $838.86 aprox. c) H = 0.9917, es decir 99.17% aprox.
Intentar resolver - Stallings 7a ejercicio 4.21
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.21
- Diseno original: Ta1 = 1 + (1 - 0.95)Tm = 1 + 0.05Tm.
- Nuevo diseno: Ta2 = 1.5 + (1 - 0.97)Tm = 1.5 + 0.03Tm.
- Conviene cambiar si Ta2 < Ta1.
- 1.5 + 0.03Tm < 1 + 0.05Tm implica 0.5 < 0.02Tm.
- Por tanto, Tm > 25 ns.
- Tiene sentido: aumentar la tasa de aciertos solo compensa el hit time mayor si la penalizacion por fallo es suficientemente grande.
Respuesta: El cambio mejora prestaciones si el tiempo/penalizacion de memoria Tm es mayor que 25 ns.
Intentar resolver - Stallings 7a ejercicio 4.22
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.22
- Linea de 64 bytes = 16 palabras de 4 bytes.
- Tiempo para traer la linea: 50 ns para la primera palabra + 15 x 5 ns = 125 ns.
- Como luego se ejecuta un acierto de cache, tiempo de acceso en fallo = 125 + 2.5 = 127.5 ns.
- Tiempo medio original = 2.5 + 0.05 x 125 = 8.75 ns.
- Linea de 128 bytes = 32 palabras. Tiempo para traerla = 50 + 31 x 5 = 205 ns.
- Nuevo tiempo medio = 2.5 + 0.03 x 205 = 8.65 ns.
- Si se incluye el acierto posterior dentro del caso de fallo, el resultado equivalente ponderado da la misma conclusion.
Respuesta: a) fallo con linea de 64 bytes: 127.5 ns total. b) Si H sube a 0.97 con linea de 128 bytes, AMAT baja de 8.75 ns a 8.65 ns; si reduce ligeramente.
Intentar resolver - Stallings 7a ejercicio 4.24
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.24
- Frecuencia 16.67 MHz implica ciclo de reloj de aproximadamente 60 ns.
- Sin estados de espera: hit = 2 ciclos, miss = 3 ciclos.
- Con H = 0.9, ciclos medios = 0.9 x 2 + 0.1 x 3 = 2.1 ciclos.
- Tiempo efectivo = 2.1 x 60 ns = 126 ns.
- Con dos estados de espera, el acceso a memoria principal pasa de 3 a 5 ciclos; hit de cache sigue en 2 ciclos.
- Ciclos medios = 0.9 x 2 + 0.1 x 5 = 2.3 ciclos.
- Tiempo efectivo = 2.3 x 60 ns = 138 ns.
Respuesta: a) 126 ns. b) 138 ns. Conclusion: una tasa alta de aciertos amortigua bastante el costo de los estados de espera.
Intentar resolver - Stallings 7a ejercicio 4.25
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.25
- 1 MIPS significa 1 millon de instrucciones por segundo, o 1 instruccion cada 1000 ns.
- Cada instruccion requiere dos ciclos de bus de 300 ns: uno para instruccion y uno para operando.
- Uso sin cache = 2 x 300 ns = 600 ns por instruccion.
- Utilizacion del bus = 600/1000 = 0.60 = 60%.
- Con cache de instrucciones H = 0.5, la captura de instruccion usa bus solo en fallos: 0.5 ciclos en promedio.
- El operando sigue usando 1 ciclo. Total = 1.5 ciclos x 300 ns = 450 ns.
- Utilizacion = 450/1000 = 45%.
Respuesta: a) 60%. b) Con cache de instrucciones de H=0.5, la utilizacion baja a 45%.
Intentar resolver - Stallings 7a ejercicio 4.26
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.26
- Para lectura, el modelo base es Ta = Tc + (1-H)Tm.
- Si Tb es el tiempo de transferir una linea completa entre cache y memoria, en un fallo hay que traer la linea: termino (1-H)Tb.
- Con escritura inmediata, cada escritura tambien actualiza memoria principal. Si W es la fraccion de escrituras, se agrega W Tm.
- Entonces: Ta = Tc + (1-H)Tb + W Tm.
- Con postescritura, una linea expulsada se escribe si fue modificada. Si Wb es la probabilidad de linea modificada, el costo extra esperado es (1-H)WbTb.
- Entonces: Ta = Tc + (1-H)Tb + (1-H)WbTb = Tc + (1-H)(1+Wb)Tb.
Respuesta: Write-through: Ta = Tc + (1-H)Tb + W Tm. Write-back: Ta = Tc + (1-H)(1+Wb)Tb.
Intentar resolver - Stallings 7a ejercicio 4.27
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.27
- Siempre se accede primero a la cache L1, por eso aparece Tc1.
- Solo se accede a L2 cuando falla L1, con probabilidad 1-H1.
- El termino esperado de L2 es (1-H1)Tc2.
- H2 es la tasa de aciertos combinada de L1 y L2; por tanto la probabilidad de llegar a memoria principal es 1-H2.
- El termino esperado de memoria principal es (1-H2)Tm.
Respuesta: Para lectura: Ta = Tc1 + (1-H1)Tc2 + (1-H2)Tm.
Intentar resolver - Stallings 7a ejercicio 4.28
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.28
- El fallo requiere 1 ciclo para enviar la direccion y 4 ciclos para acceder/transferir una palabra de 32 bits.
- a) Linea de una palabra: 1 + 4 = 5 ciclos.
- b) Linea de cuatro palabras sin rafaga: se repite el acceso completo por palabra, 4 x (1+4) = 20 ciclos.
- c) Linea de cuatro palabras con rafaga: 1 ciclo de direccion + 4 ciclos para la primera palabra + 1 ciclo por cada una de las otras 3 palabras = 8 ciclos.
Respuesta: a) 5 ciclos. b) 20 ciclos. c) 8 ciclos.
Intentar resolver - Stallings 7a ejercicio 4.29
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Stallings 7a ejercicio 4.29
- Del problema 4.28: penalizacion con linea de una palabra = 5 ciclos.
- Con tasa de fallos 3.2%, penalizacion media = 0.032 x 5 = 0.16 ciclos por lectura.
- Para linea de cuatro palabras sin rafaga, penalizacion = 20 ciclos y tasa de fallos = 1.1%.
- Penalizacion media sin rafaga = 0.011 x 20 = 0.22 ciclos por lectura.
- Para linea de cuatro palabras con rafaga, penalizacion = 8 ciclos.
- Penalizacion media con rafaga = 0.011 x 8 = 0.088 ciclos por lectura.
Respuesta: Linea de 1 palabra: 0.16 ciclos/lectura. Linea de 4 sin rafaga: 0.22 ciclos/lectura. Linea de 4 con rafaga: 0.088 ciclos/lectura.
Patterson/Hennessy
Intentar resolver - Patterson/Hennessy ejercicio 5.3
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.3
- Para 5.3.1 use bloques de una palabra: indice = direccion mod 16; etiqueta = piso(direccion/16).
- Con esa regla, la secuencia a produce 1 acierto y 11 fallos; la secuencia b produce 1 acierto y 11 fallos.
- Para 5.3.2 use bloque = piso(direccion/2), desplazamiento = direccion mod 2, indice = bloque mod 8 y etiqueta = piso(bloque/8).
- Con bloques de dos palabras, la secuencia a produce 3 aciertos y 9 fallos; la secuencia b produce 4 aciertos y 8 fallos.
- Para comparar disenos use AMAT = tiempo de acierto + tasa de fallos x penalizacion de fallo. Para calcular bits totales sume datos, etiqueta y bit valido por entrada.
Respuesta: 5.3.1: a = 1/12 aciertos, b = 1/12 aciertos. 5.3.2: a = 3/12 aciertos, b = 4/12 aciertos. El resto se completa con AMAT y conteo de bits segun el diseno elegido.
Intentar resolver - Patterson/Hennessy ejercicio 5.4
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.4
- Caso a: desplazamiento 3..0 = 4 bits, por tanto la linea tiene 16 bytes = 4 palabras. El indice 9..4 tiene 6 bits, asi que hay 64 entradas.
- Caso a: etiqueta 31..10 = 22 bits. Bits totales = 64 x (128 datos + 22 etiqueta + 1 valido) = 9664 bits; datos = 8192 bits.
- Caso b: desplazamiento 4..0 = 5 bits, por tanto la linea tiene 32 bytes = 8 palabras. El indice 11..5 tiene 7 bits, asi que hay 128 entradas.
- Caso b: etiqueta 31..12 = 20 bits. Bits totales = 128 x (256 datos + 20 etiqueta + 1 valido) = 35456 bits; datos = 32768 bits.
- Simulando las referencias desde cache vacia: en a hay 3 aciertos, 9 fallos y 3 reemplazos; en b hay 5 aciertos, 7 fallos y 0 reemplazos.
Respuesta: a) linea = 4 palabras, entradas = 64, total/datos = 9664/8192 = 1.18, razon de aciertos = 3/12 = 25%. b) linea = 8 palabras, entradas = 128, total/datos = 35456/32768 = 1.08, razon de aciertos = 5/12 = 41.67%.
Intentar resolver - Patterson/Hennessy ejercicio 5.5
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.5
- Separe la politica de escritura de la politica de reserva: escritura retardada usa bloques sucios y escritura directa envia cada escritura al siguiente nivel.
- Entre L1 y L2 se necesitan buffers de relleno para traer bloques y buffers de escritura o victima para expulsar bloques modificados.
- Entre L2 y memoria, una L2 de escritura directa necesita buffer de escritura para absorber trafico hacia memoria.
- Para los incisos de ancho de banda, use ciclos = CPI x 1000 instrucciones. Divida los bytes transferidos por esos ciclos.
- En escritura directa cuente las escrituras de datos hacia el siguiente nivel; en escritura retardada cuente los write-backs solo cuando el bloque expulsado este sucio.
Respuesta: Use la tabla para contar trafico por 1000 instrucciones. Lecturas minimas vienen de fallos que traen bloques; escrituras minimas vienen de escrituras directas o de bloques sucios expulsados, segun la politica.
Intentar resolver - Patterson/Hennessy ejercicio 5.6
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.6
- La secuencia accede palabras consecutivas de 4 bytes. Con linea de 32 bytes, cada fallo trae 8 accesos utiles.
- Para lineas de 16, 32, 64 y 128 bytes, las frecuencias de fallo aproximadas son 1/4, 1/8, 1/16 y 1/32.
- La prebusqueda secuencial reduce casi todos los fallos despues del arranque si el buffer alcanza a traer la linea siguiente a tiempo.
- Para elegir tamano de bloque, compare tasa de fallos x penalizacion. Con penalizacion 20 x B, gana 16 B en la fila a y 8 B en la fila b.
- Con penalizacion 24 + B, gana 32 B en la fila a y 8 B en la fila b. Con penalizacion constante, gana 64 B en ambas filas porque tiene la menor tasa de fallos.
Respuesta: 5.6.1: 12.5% con linea de 32 B. 5.6.2: 16 B = 25%, 64 B = 6.25%, 128 B = 3.125%. 5.6.4: a = 16 B, b = 8 B. 5.6.5: a = 32 B, b = 8 B. 5.6.6: 64 B.
Intentar resolver - Patterson/Hennessy ejercicio 5.7
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.7
- La frecuencia de reloj es 1 / tiempo de acierto de L1. Para la fila a: P1 = 1.61 GHz y P2 = 1.52 GHz. Para la fila b: P1 = 1.04 GHz y P2 = 0.93 GHz.
- AMAT sin L2 = tiempo de acierto L1 + tasa de fallos L1 x 70 ns. Fila a: P1 = 8.60 ns, P2 = 6.26 ns. Fila b: P1 = 3.97 ns, P2 = 3.46 ns.
- Con CPI base 1 y 36% de accesos a memoria, tiempo por instruccion = ciclo + 0.36 x tasa de fallos x 70 ns.
- Sin L2, P2 es mas rapido en ambas filas: fila a P1 = 3.49 ns/instr y P2 = 2.68 ns/instr; fila b P1 = 2.04 ns/instr y P2 = 1.94 ns/instr.
- Con L2 en P1, use AMAT = L1 + MR1 x (L2 + MR2 x memoria). Fila a: 8.81 ns. Fila b: 3.65 ns.
Respuesta: Sin L2 gana P2 en ambas filas. Con L2 para P1: fila a sigue ganando P2; P1 necesitaria bajar su fallo L1 a cerca de 7.95% para empatar. Fila b gana P1 por poco; P2 necesitaria cerca de 3.37% de fallo L1 para empatar.
Intentar resolver - Patterson/Hennessy ejercicio 5.8
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Patterson/Hennessy ejercicio 5.8
- Para 5.8.1 a 5.8.3 simule cada referencia del ejercicio 5.3 usando LRU o MRU y actualice el orden de uso despues de cada acierto o fallo.
- Para 5.8.4 use CPI = CPI base + fallos L1 por instruccion x tiempo L2 + fallos globales por instruccion x penalizacion de memoria.
- Fila a: memoria principal = 125 ns y procesador = 3 GHz, por tanto la penalizacion de memoria es 375 ciclos.
- Fila b: memoria principal = 100 ns y procesador = 1 GHz, por tanto la penalizacion de memoria es 100 ciclos.
- Al duplicar o partir a la mitad el tiempo de memoria, solo cambia el termino de penalizacion de memoria; los ciclos de L2 quedan iguales.
Respuesta: Fila a: solo L1 = 20.75 CPI, L2 directa = 14.00 CPI, L2 8 vias = 10.00 CPI. Si memoria se duplica: 39.50, 25.25, 16.75. Si se reduce a la mitad: 11.38, 8.38, 6.63. Fila b: solo L1 = 6.00 CPI, L2 directa = 6.40 CPI, L2 8 vias = 4.40 CPI. Si memoria se duplica: 10.00, 10.40, 6.00. Si se reduce a la mitad: 4.00, 4.40, 3.60.
Intentar resolver - Patterson/Hennessy ejercicio 5.12
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.
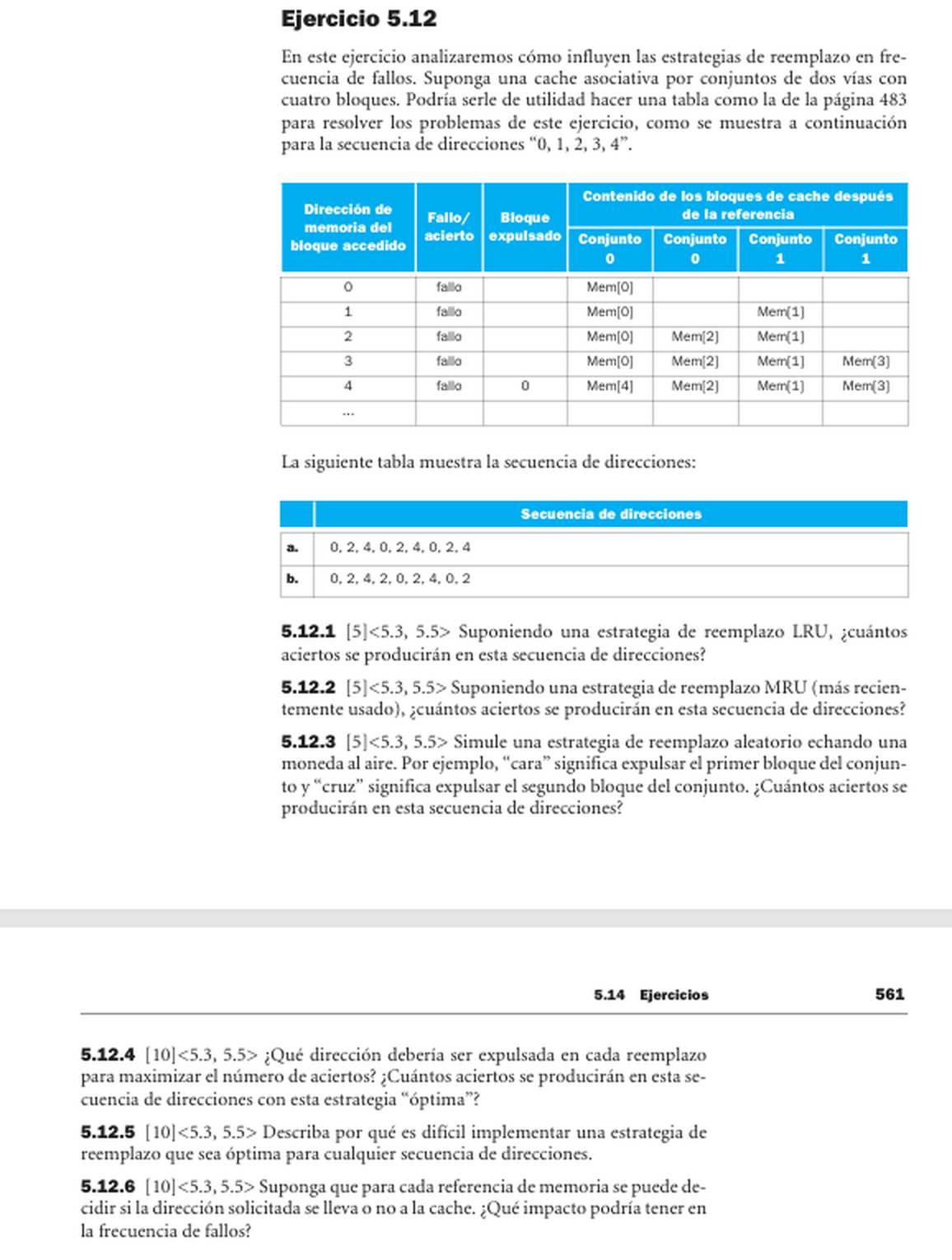
Solucion - Patterson/Hennessy ejercicio 5.12
- La cache tiene dos conjuntos y dos vias. Los bloques 0, 2 y 4 caen en el mismo conjunto porque son pares.
- Secuencia a: 0, 2, 4, 0, 2, 4. Con LRU se expulsa siempre el bloque que se necesita despues, por eso hay 0 aciertos.
- En la misma secuencia a, MRU logra 2 aciertos y una estrategia optima tambien logra 2 aciertos.
- Secuencia b: 0, 2, 4, 2, 0, 2, 4, 0, 2. LRU logra 2 aciertos; MRU logra 3 aciertos; la optima logra 3 aciertos.
- La estrategia aleatoria depende de la secuencia de moneda. Para maximizar aciertos se expulsa el bloque cuyo proximo uso esta mas lejos.
Respuesta: Secuencia a: LRU = 0 aciertos, MRU = 2, optima = 2. Secuencia b: LRU = 2 aciertos, MRU = 3, optima = 3. La aleatoria no tiene un unico resultado sin fijar las monedas.
Null/Lobur
Intentar resolver - Null/Lobur ejercicio 1
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 1
- Memoria principal: 2^20 palabras. Bloque: 16 palabras = 2^4, asi que el campo palabra ocupa 4 bits.
- La cache tiene 32 bloques = 2^5, asi que el campo bloque de cache ocupa 5 bits.
- La etiqueta ocupa 20 - 5 - 4 = 11 bits.
- Para 0DB63_16: numero de bloque = 0DB63_16 >> 4 = 0DB6_16. Bloque de cache = 0DB6_16 mod 32 = 16_16 = 22 decimal.
Respuesta: Hay 2^16 bloques de memoria principal. Formato: etiqueta = 11 bits, bloque = 5 bits, palabra = 4 bits. La referencia 0DB63_16 mapea al bloque de cache 22.
Intentar resolver - Null/Lobur ejercicio 2
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 2
- Memoria principal: 2^32 palabras. Bloque: 32 palabras = 2^5, asi que palabra ocupa 5 bits.
- La cache tiene 1024 bloques = 2^10, asi que el campo bloque ocupa 10 bits.
- La etiqueta ocupa 32 - 10 - 5 = 17 bits.
- Para 000063FA_16: numero de bloque = 31F_16 = 799 decimal. Como la cache tiene 1024 bloques, mapea al bloque 799.
Respuesta: Hay 2^27 bloques de memoria principal. Formato: etiqueta = 17 bits, bloque = 10 bits, palabra = 5 bits. La referencia 000063FA_16 mapea al bloque de cache 799.
Intentar resolver - Null/Lobur ejercicio 3
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 3
- Memoria principal: 2^16 palabras. Bloque: 32 palabras = 2^5, asi que palabra ocupa 5 bits.
- Numero de bloques de memoria principal = 2^16 / 2^5 = 2^11.
- En una cache totalmente asociativa no hay campo de indice o bloque de cache en la direccion.
- La referencia F8C9_16 tiene etiqueta/bloque F8C9_16 >> 5 = 7C6_16 y desplazamiento 9.
Respuesta: Hay 2^11 bloques de memoria principal. Formato: etiqueta = 11 bits y palabra = 5 bits. La referencia F8C9_16 puede mapear a cualquier bloque de la cache.
Intentar resolver - Null/Lobur ejercicio 4
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 4
- Memoria principal: 2^24 palabras. Bloque: 64 palabras = 2^6, asi que palabra ocupa 6 bits.
- Numero de bloques de memoria principal = 2^24 / 2^6 = 2^18.
- Al ser totalmente asociativa, no hay campo de indice.
- La referencia 01D872_16 tiene etiqueta/bloque 01D872_16 >> 6 = 761_16 y desplazamiento 32_16.
Respuesta: Hay 2^18 bloques de memoria principal. Formato: etiqueta = 18 bits y palabra = 6 bits. La referencia 01D872_16 puede mapear a cualquier bloque de la cache.
Intentar resolver - Null/Lobur ejercicio 5
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 5
- Memoria principal: 128M palabras = 2^27 palabras.
- Bloque: 64 palabras = 2^6, asi que palabra ocupa 6 bits.
- La cache tiene 32K bloques = 2^15 bloques. Como es de dos vias, hay 2^14 conjuntos.
- El conjunto ocupa 14 bits y la etiqueta ocupa 27 - 14 - 6 = 7 bits.
Respuesta: Formato de direccion: etiqueta = 7 bits, conjunto = 14 bits, palabra = 6 bits.
Intentar resolver - Null/Lobur ejercicio 6
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 6
- La memoria principal tiene 2K bloques = 2^11 bloques y cada bloque tiene 8 palabras = 2^3.
- La cache tiene 4 conjuntos = 2^2. Por eso el conjunto ocupa 2 bits y la palabra 3 bits.
- Etiqueta = 11 - 2 = 9 bits.
- El programa accede de 8 a 51: son 44 referencias por vuelta y 132 en tres vueltas. Los bloques usados son 1 a 6, seis bloques en total.
- La cache de 4 conjuntos y 2 vias puede contener esos seis bloques sin expulsarlos despues de cargarlos. Solo hay 6 fallos iniciales.
Respuesta: Formato: etiqueta = 9 bits, conjunto = 2 bits, palabra = 3 bits. Razon de aciertos = 126/132 = 21/22.
Intentar resolver - Null/Lobur ejercicio 7
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 7
- Memoria principal: 2^16 palabras. Bloque: 8 palabras = 2^3, asi que palabra ocupa 3 bits.
- La cache tiene 32 bloques.
- Si es de 2 vias: conjuntos = 32/2 = 16 = 2^4, entonces conjunto ocupa 4 bits y etiqueta = 16 - 4 - 3 = 9 bits.
- Si es de 4 vias: conjuntos = 32/4 = 8 = 2^3, entonces conjunto ocupa 3 bits y etiqueta = 16 - 3 - 3 = 10 bits.
Respuesta: 2 vias: etiqueta = 9, conjunto = 4, palabra = 3. 4 vias: etiqueta = 10, conjunto = 3, palabra = 3.
Intentar resolver - Null/Lobur ejercicio 8
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 8
- Memoria principal: 2^21 palabras. Bloque: 4 palabras = 2^2, asi que palabra ocupa 2 bits.
- La cache tiene 64 bloques.
- Si es de 2 vias: conjuntos = 64/2 = 32 = 2^5, etiqueta = 21 - 5 - 2 = 14 bits.
- Si es de 4 vias: conjuntos = 64/4 = 16 = 2^4, etiqueta = 21 - 4 - 2 = 15 bits.
Respuesta: 2 vias: etiqueta = 14, conjunto = 5, palabra = 2. 4 vias: etiqueta = 15, conjunto = 4, palabra = 2.
Intentar resolver - Null/Lobur ejercicio 9
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.
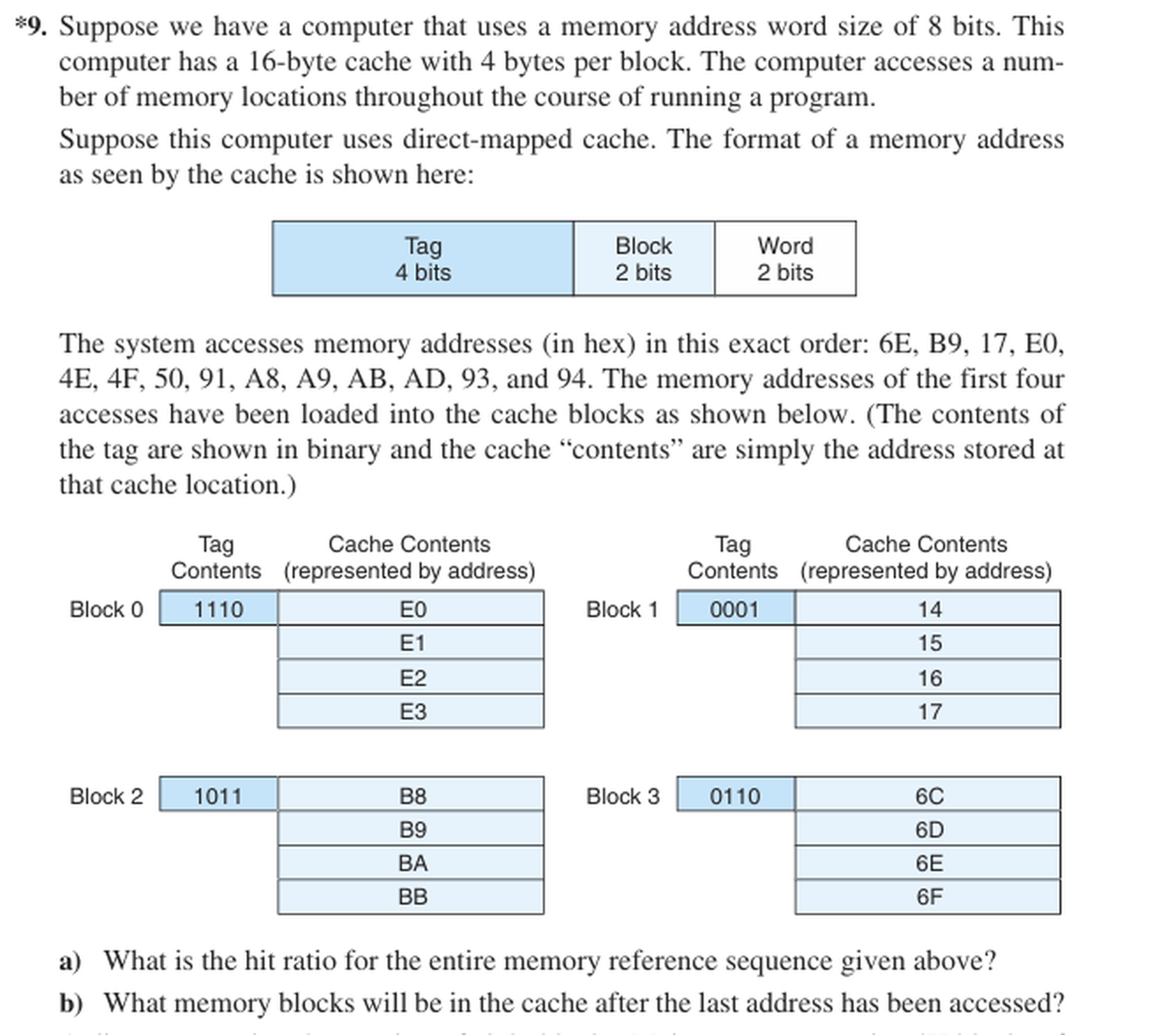
Solucion - Null/Lobur ejercicio 9
- La direccion tiene 8 bits. La cache tiene 16 bytes con bloques de 4 bytes: palabra = 2 bits y bloque de cache = 2 bits.
- La etiqueta ocupa 8 - 2 - 2 = 4 bits.
- Despues de las primeras cuatro referencias la cache contiene los bloques de E0, 14, B8 y 6C como muestra la captura.
- Para las referencias restantes: 4E falla, 4F acierta, 50 falla, 91 falla, A8 falla, A9 acierta, AB acierta, AD falla, 93 acierta, 94 falla.
- Si se cuenta la secuencia completa desde cache vacia, las primeras cuatro referencias tambien son fallos. Si se parte desde el estado ya cargado, solo se cuentan las diez restantes.
Respuesta: Formato: etiqueta = 4 bits, bloque = 2 bits, palabra = 2 bits. Desde el estado mostrado: 4 aciertos de 10 = 40%. Contando toda la secuencia desde cache vacia: 4 aciertos de 14 = 28.57%.
Intentar resolver - Null/Lobur ejercicio 10
Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.

Solucion - Null/Lobur ejercicio 10
- Memoria principal: 4K bloques = 2^12 bloques, con 8 palabras por bloque = 2^3.
- La cache tiene 8 bloques = 2^3. Por tanto etiqueta = 12 - 3 = 9 bits, bloque de cache = 3 bits y palabra = 3 bits.
- El programa recorre 0 a 67, es decir 68 referencias por vuelta. Usa los bloques 0 a 8.
- Primera vuelta: 9 fallos, uno por bloque. Al final, el bloque 8 reemplaza al bloque 0.
- Cada una de las otras tres vueltas tiene 2 fallos: al volver a bloque 0 y luego al llegar a bloque 8. Total: 15 fallos en 272 accesos.
- Tiempo efectivo = 22 ns + tasa de fallos x 300 ns, porque cada acceso busca en cache y el fallo agrega el llenado del bloque.
Respuesta: Formato: etiqueta = 9 bits, bloque = 3 bits, palabra = 3 bits. Razon de aciertos = 257/272 = 94.49%. Tiempo efectivo aproximado = 22 + (15/272) x 300 = 38.54 ns.
Pagina 7 de 8
Apendices A y B
Apendice A: Otros ejercicios recomendados
Ejercicios extra relacionados con el segundo parcial. No tienen captura ni solucion aqui; usalos como practica adicional si ya terminaste el banco principal.
<div class="notice">
<strong>Uso sugerido:</strong> prioriza primero los ejercicios del checklist con solucion. Despues toma 3 a 5 ejercicios de este apendice por tema debil y resuelvelos justificando cada paso.
</div>
<div class="block">
<div>
<div class="time">Stallings 10a</div>
<div class="small">Capitulo 4</div>
</div>
<div>
<h3>Computer Organization and Architecture, 10th Edition</h3>
<table>
<thead>
<tr>
<th>Tema</th>
<th>Ejercicios recomendados</th>
</tr>
</thead>
<tbody>
<tr>
<td>Conceptos de jerarquia, localidad y tipos de acceso</td>
<td>Review Questions 4.1-4.9.</td>
</tr>
<tr>
<td>Campos de direccion y estructura de cache</td>
<td>Problems 4.4, 4.11.</td>
</tr>
<tr>
<td>Reemplazo y LRU</td>
<td>Problems 4.9, 4.13.</td>
</tr>
<tr>
<td>Bloques, transferencia y penalizacion</td>
<td>Problem 4.14.</td>
</tr>
<tr>
<td>Jerarquias de varios niveles y rendimiento</td>
<td>Problems 4.16, 4.19, 4.20, 4.21, 4.22.</td>
</tr>
<tr>
<td>Politicas de escritura y trafico de memoria</td>
<td>Problem 4.23.</td>
</tr>
</tbody>
</table>
</div>
</div>
<div class="block">
<div>
<div class="time">Enfoque cuantitativo</div>
<div class="small">Capitulo 2</div>
</div>
<div>
<h3>Computer Architecture: A Quantitative Approach</h3>
<table>
<thead>
<tr>
<th>Tema</th>
<th>Ejercicios recomendados</th>
</tr>
</thead>
<tbody>
<tr>
<td>Localidad, bloqueo y transposicion de matrices</td>
<td>Exercises 2.1, 2.2, 2.3.</td>
</tr>
<tr>
<td>Medicion de jerarquia de memoria, cache L2 y TLB</td>
<td>Exercises 2.4, 2.5.</td>
</tr>
<tr>
<td>Memoria en multiprocesador y cache de instrucciones</td>
<td>Exercises 2.6, 2.7.</td>
</tr>
<tr>
<td>CACTI, asociatividad, tiempo de acceso y AMAT</td>
<td>Exercise 2.8.</td>
</tr>
<tr>
<td>Way prediction y cache L1</td>
<td>Exercise 2.9.</td>
</tr>
<tr>
<td>Cache L1 banked vs pipelined</td>
<td>Exercise 2.10.</td>
</tr>
<tr>
<td>Critical word first y early restart</td>
<td>Exercise 2.11.</td>
</tr>
<tr>
<td>Write buffers y merging buffers</td>
<td>Exercise 2.12.</td>
</tr>
<tr>
<td>DRAM, ancho de banda, latencia y energia</td>
<td>Exercises 2.13, 2.14, 2.15, 2.16, 2.17, 2.18, 2.19.</td>
</tr>
</tbody>
</table>
</div>
</div>
Apendice B: Ejercicios de pauta
Ejercicios de pauta agregados como practica interactiva con captura, intento y solucion de referencia.
<div class="notice">
<strong>Uso:</strong> intenta resolver cada ejercicio con la captura antes de abrir la solucion. Si una respuesta depende de una interpretacion del enunciado, queda indicado en el procedimiento.
</div>
<div class="block">
<div>
<div class="time">Pauta</div>
<div class="small">Cache y mapeo</div>
</div>
<div>
<h3>Ejercicios de pauta</h3>
<div class="tasks">
<label><input type="checkbox"><span>Resolver pauta ejercicio 1: cache asociativa por conjuntos, etiquetas y conjuntos.<span class="attachments"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-1.png" target="_blank">Captura 1</a></span></span></label>
<div class="exercise-tools">
<div class="exercise-action-row">
<button type="button" data-toggle-panel="pauta-1-try" aria-expanded="false">Intentar resolver</button>
<button type="button" data-toggle-panel="pauta-1-solution" aria-expanded="false">Ver solucion</button>
</div>
<section id="pauta-1-try" class="exercise-panel" hidden>
<h4>Intentar resolver - Pauta ejercicio 1</h4>
<p class="small">Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.</p>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-1.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-1.png" alt="Pauta ejercicio 1"></a></div>
<label for="pauta-1-answer" class="small"><strong>Tu respuesta</strong></label>
<textarea id="pauta-1-answer" class="answer-input" placeholder="Escribe aqui tu procedimiento y resultado."></textarea>
</section>
<section id="pauta-1-solution" class="exercise-panel" hidden>
<h4>Solucion - Pauta ejercicio 1</h4>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-1.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-1.png" alt="Pauta ejercicio 1"></a></div>
<ol><li>La linea tiene 8 palabras de 16 bits: 8 x 16 = 128 bits = 16 bytes.</li><li>La cache tiene 16 KB, asi que contiene 16 KB / 16 B = 1024 lineas.</li><li>Si se usa k = 8 como ocho vias, entonces conjuntos = 1024 / 8 = 128 conjuntos.</li><li>La memoria principal de 16 MB tiene 16 MB / 16 B = 1,048,576 bloques = 2^20 bloques.</li><li>Con 128 conjuntos, los bits de conjunto son 7 y los bits de etiqueta son 20 - 7 = 13.</li><li>Bloques por etiqueta = 2^7 = 128. Numero de etiquetas = 2^13 = 8192.</li><li>El bloque 1200 se asigna al conjunto 1200 mod 128 = 48.</li><li>El byte 1200 pertenece al bloque piso(1200 / 16) = 75, por tanto se asigna al conjunto 75 mod 128 = 75.</li></ol>
<p><strong>Respuesta:</strong> Usando k = 8 y los tamanos de memoria/cache: a) 128 bloques por etiqueta. b) 8192 etiquetas. c) 128 conjuntos. d) bloque 1200 -> conjunto 48. e) byte 1200 -> conjunto 75. Nota: la frase "4096 bloques por conjunto" no es consistente con esos datos; si se toma esa frase como dato dominante, saldrian 256 conjuntos, 4096 etiquetas y el bloque 1200 iria al conjunto 176.</p>
</section>
</div>
<label><input type="checkbox"><span>Resolver pauta ejercicio 2: cache directa, capacidad, etiquetas y linea destino.<span class="attachments"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-2.png" target="_blank">Captura 2</a></span></span></label>
<div class="exercise-tools">
<div class="exercise-action-row">
<button type="button" data-toggle-panel="pauta-2-try" aria-expanded="false">Intentar resolver</button>
<button type="button" data-toggle-panel="pauta-2-solution" aria-expanded="false">Ver solucion</button>
</div>
<section id="pauta-2-try" class="exercise-panel" hidden>
<h4>Intentar resolver - Pauta ejercicio 2</h4>
<p class="small">Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.</p>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-2.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-2.png" alt="Pauta ejercicio 2"></a></div>
<label for="pauta-2-answer" class="small"><strong>Tu respuesta</strong></label>
<textarea id="pauta-2-answer" class="answer-input" placeholder="Escribe aqui tu procedimiento y resultado."></textarea>
</section>
<section id="pauta-2-solution" class="exercise-panel" hidden>
<h4>Solucion - Pauta ejercicio 2</h4>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-2.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-2.png" alt="Pauta ejercicio 2"></a></div>
<ol><li>La figura muestra 256 lineas y 512 bits de datos por linea.</li><li>512 bits = 64 bytes por linea, asi que la capacidad de datos de la cache es 256 x 64 B = 16 KB.</li><li>El campo etiqueta tiene 18 bits y el campo linea tiene 8 bits.</li><li>Para una etiqueta fija, los 8 bits de linea permiten 2^8 = 256 bloques.</li><li>Para una linea fija, los 18 bits de etiqueta permiten 2^18 etiquetas posibles.</li><li>Cada linea tiene 512 bits = 16 palabras de 32 bits; por etiqueta hay 256 lineas x 16 palabras = 4096 palabras.</li><li>La direccion de byte 16384 cae en el bloque piso(16384 / 64) = 256. En cache directa: linea = 256 mod 256 = 0.</li></ol>
<p><strong>Respuesta:</strong> a) 16 KB. b) 256 bloques por etiqueta. c) 2^18 etiquetas por linea de cache. d) 4096 palabras por etiqueta. e) la direccion de byte 16384 se asigna a la linea 0.</p>
</section>
</div>
<label><input type="checkbox"><span>Resolver pauta ejercicio 3: sustitucion LRU con contadores de 2 bits.<span class="attachments"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-3.png" target="_blank">Captura 3</a></span></span></label>
<div class="exercise-tools">
<div class="exercise-action-row">
<button type="button" data-toggle-panel="pauta-3-try" aria-expanded="false">Intentar resolver</button>
<button type="button" data-toggle-panel="pauta-3-solution" aria-expanded="false">Ver solucion</button>
</div>
<section id="pauta-3-try" class="exercise-panel" hidden>
<h4>Intentar resolver - Pauta ejercicio 3</h4>
<p class="small">Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.</p>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-3.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-3.png" alt="Pauta ejercicio 3"></a></div>
<label for="pauta-3-answer" class="small"><strong>Tu respuesta</strong></label>
<textarea id="pauta-3-answer" class="answer-input" placeholder="Escribe aqui tu procedimiento y resultado."></textarea>
</section>
<section id="pauta-3-solution" class="exercise-panel" hidden>
<h4>Solucion - Pauta ejercicio 3</h4>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-3.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-3.png" alt="Pauta ejercicio 3"></a></div>
<ol><li>Use 0 como mas reciente y 3 como menos reciente. Estado inicial: A=3, B=2, C=1, D=0.</li><li>Secuencia: A, B, C, D, B, E, D, A, C, E, C, F.</li><li>Los accesos A, B, C, D y B son aciertos. Al llegar E hay fallo y se reemplaza A.</li><li>D es acierto. Al llegar A hay fallo y se reemplaza C.</li><li>Al llegar C hay fallo y se reemplaza B. Luego E y C son aciertos.</li><li>Al llegar F hay fallo y se reemplaza D.</li><li>Conteo total: 8 aciertos y 4 fallos en 12 referencias.</li></ol>
<p><strong>Respuesta:</strong> La tasa de aciertos es H = 8/12 = 2/3 = 66.67%.</p>
</section>
</div>
<label><input type="checkbox"><span>Resolver pauta ejercicio 4: cache directa con direcciones de byte y razon de aciertos.<span class="attachments"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-4.png" target="_blank">Captura 4</a></span></span></label>
<div class="exercise-tools">
<div class="exercise-action-row">
<button type="button" data-toggle-panel="pauta-4-try" aria-expanded="false">Intentar resolver</button>
<button type="button" data-toggle-panel="pauta-4-solution" aria-expanded="false">Ver solucion</button>
</div>
<section id="pauta-4-try" class="exercise-panel" hidden>
<h4>Intentar resolver - Pauta ejercicio 4</h4>
<p class="small">Resuelve primero sin mirar la solucion. Puedes escribir tu procedimiento o respuesta aqui.</p>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-4.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-4.png" alt="Pauta ejercicio 4"></a></div>
<label for="pauta-4-answer" class="small"><strong>Tu respuesta</strong></label>
<textarea id="pauta-4-answer" class="answer-input" placeholder="Escribe aqui tu procedimiento y resultado."></textarea>
</section>
<section id="pauta-4-solution" class="exercise-panel" hidden>
<h4>Solucion - Pauta ejercicio 4</h4>
<div class="capture-grid"><a href="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-4.png" target="_blank"><img src="/study/arquitectura-parcial-2/capturas/Pauta%20ejercicios/pauta-4.png" alt="Pauta ejercicio 4"></a></div>
<ol><li>El desplazamiento usa bits 3-0: 2^4 = 16 bytes por linea.</li><li>Como las palabras son de 32 bits = 4 bytes, cada linea tiene 16 / 4 = 4 palabras.</li><li>El campo linea usa bits 9-4: 6 bits, por tanto hay 2^6 = 64 lineas.</li><li>Datos por linea = 16 bytes = 128 bits. Con etiqueta de 22 bits y 1 bit valido, bits por linea = 128 + 22 + 1 = 151.</li><li>Relacion bits totales/datos = (64 x 151) / (64 x 128) = 9664 / 8192 = 1.18.</li><li>Para las direcciones dadas, el bloque es piso(direccion / 16) y la linea es bloque mod 64.</li><li>La secuencia produce aciertos en 4, 30 y 140. Hay 3 aciertos y 9 fallos.</li><li>Los reemplazos ocurren cuando un fallo cae en una linea ya ocupada: 1024, 3100 y 2180. Total: 3 reemplazos.</li></ol>
<p><strong>Respuesta:</strong> a) 4 palabras de 32 bits. b) relacion = 9664/8192 = 1.18. c) 3 bloques reemplazados. d) tasa de aciertos = 3/12 = 25%.</p>
</section>
</div>
</div>
</div>
</div>
Pagina 8 de 8
Apendices C y D
Apendice C: Morris Mano
Lecturas y ejercicios del libro de Morris Mano relacionados con sistema de memoria, organizacion de memoria, transferencia entre registros, formatos de instruccion y modos de direccionamiento.
<div class="notice">
<strong>Uso sugerido:</strong> este libro complementa mejor la base de memoria principal, registros MAR/MBR, ciclos de lectura/escritura y direccionamiento. Para cache, sigue priorizando Stallings, Null/Lobur y Patterson/Hennessy; en Morris Mano usa estas secciones como refuerzo conceptual.
</div>
<div class="mini-grid">
<div class="card">
<h3>Ruta de 30 minutos</h3>
<p>Lee 7-7 y resuelve 7-32. Objetivo: dominar bits de direccion, tamano de palabra, MAR y MBR.</p>
</div>
<div class="card">
<h3>Ruta de 60 minutos</h3>
<p>Agrega 7-8 y los ejercicios 7-33 y 7-34. Objetivo: entender seleccion de palabra y expansion de memoria.</p>
</div>
<div class="card">
<h3>Ruta de 90 minutos</h3>
<p>Agrega 8-11, 12-3 y 12-4. Objetivo: conectar instrucciones, ciclos de memoria y modos de direccionamiento.</p>
</div>
</div>
<div class="block">
<div>
<div class="time">Lecturas</div>
<div class="small">Morris Mano</div>
</div>
<div>
<h3>Que leer para el parcial</h3>
<table>
<thead>
<tr>
<th>Prioridad</th>
<th>Capitulo/seccion</th>
<th>Paginas</th>
<th>Para que sirve</th>
</tr>
</thead>
<tbody>
<tr>
<td>Alta</td>
<td>Cap. 7, seccion 7-7: La unidad de memoria</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=306" target="_blank">Libro p. 300-306 / PDF p. 306-312</a></td>
<td>Refuerza memoria principal, MAR, MBR, lectura, escritura, tiempo de acceso, memoria volatil/no volatil y lectura destructiva/no destructiva.</td>
</tr>
<tr>
<td>Alta</td>
<td>Cap. 7, seccion 7-8: Ejemplos de memoria de acceso aleatorio</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=312" target="_blank">Libro p. 306-312 / PDF p. 312-318</a></td>
<td>Practica la idea de celda binaria, seleccion de palabra, decodificadores, arreglo de memoria y organizacion RAM.</td>
</tr>
<tr>
<td>Media</td>
<td>Cap. 8, secciones 8-1 y 8-2: Logica de transferencia de registros</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=322" target="_blank">Libro p. 316-326 / PDF p. 322-332</a></td>
<td>Ayuda a justificar operaciones tipo M[dir], transferencias entre registros, buses, control y notacion RTL.</td>
</tr>
<tr>
<td>Media</td>
<td>Cap. 8, secciones 8-3 a 8-10: Microoperaciones aritmeticas, logicas y de desplazamiento</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=333" target="_blank">Libro p. 327-352 / PDF p. 333-358</a></td>
<td>Refuerzo para desplazamientos, mascaras, operaciones logicas y manipulacion de bits si aparecen como base de ejercicios.</td>
</tr>
<tr>
<td>Media</td>
<td>Cap. 8, secciones 8-11 y 8-12: Codigos de instruccion y computador sencillo</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=358" target="_blank">Libro p. 352-366 / PDF p. 358-372</a></td>
<td>Conecta formato de instruccion, opcode, operando inmediato, direccion directa, macrooperaciones y microoperaciones.</td>
</tr>
<tr>
<td>Media</td>
<td>Cap. 12, seccion 12-3: Organizacion del microprocesador</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=532" target="_blank">Libro p. 526-534 / PDF p. 532-540</a></td>
<td>Revisa buses de datos/direcciones, ciclo de memoria, lectura, escritura, PC, AR e interaccion CPU-memoria.</td>
</tr>
<tr>
<td>Media</td>
<td>Cap. 12, seccion 12-4: Instrucciones y modos de direccionamiento</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=540" target="_blank">Libro p. 534-542 / PDF p. 540-547</a></td>
<td>Resume instrucciones de transferencia/operacion/control y modos implicito, registro, indirecto de registro, inmediato, directo, pagina cero, pagina presente, relativo, indexado, base e indirecto.</td>
</tr>
</tbody>
</table>
</div>
</div>
<div class="block">
<div>
<div class="time">Ejercicios</div>
<div class="small">Morris Mano</div>
</div>
<div>
<h3>Lista recomendada para resolver</h3>
<table>
<thead>
<tr>
<th>Ejercicios</th>
<th>Tema</th>
<th>Ubicacion</th>
<th>Por que conviene resolverlos</th>
</tr>
</thead>
<tbody>
<tr>
<td>7-32</td>
<td>Capacidad de memoria, MAR y MBR</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=321" target="_blank">Problemas cap. 7 / PDF p. 321</a></td>
<td>Entrena el calculo de bits de direccion, tamano de palabra y cantidad de palabras, que es base para cache y campos de direccion.</td>
</tr>
<tr>
<td>7-33</td>
<td>Seleccion de celdas y decodificadores</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=321" target="_blank">Problemas cap. 7 / PDF p. 321</a></td>
<td>Refuerza como se selecciona una palabra en memoria usando entradas X/Y y decodificadores.</td>
</tr>
<tr>
<td>7-34</td>
<td>Expansion de memoria RAM</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=321" target="_blank">Problemas cap. 7 / PDF p. 321</a></td>
<td>Practica construir memorias mayores a partir de modulos menores, idea util para interpretar organizacion por bloques.</td>
</tr>
<tr>
<td>7-35</td>
<td>Organizacion fisica de memoria</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=321" target="_blank">Problemas cap. 7 / PDF p. 321</a></td>
<td>Relaciona palabras, bits por palabra, matrices y registros de direccion/buffer; es buen ejercicio de conteo y estructura.</td>
</tr>
<tr>
<td>8-6 y 8-7</td>
<td>Transferencias con memoria</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=373" target="_blank">Problemas cap. 8 / PDF p. 373</a></td>
<td>Sirven para practicar lectura/escritura, MBR, memoria y seleccion de registros mediante multiplexores/decodificadores.</td>
</tr>
<tr>
<td>8-12, 8-19 y 8-20</td>
<td>Desplazamientos</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=374" target="_blank">Problemas cap. 8 / PDF p. 374-375</a></td>
<td>Recomendados si necesitas reforzar desplazamiento logico y aritmetico como soporte de operaciones de datos.</td>
</tr>
<tr>
<td>8-28</td>
<td>Formato de instruccion</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=376" target="_blank">Problemas cap. 8 / PDF p. 376</a></td>
<td>Pide bits de opcode, bits de direccion y cantidad de palabras; es directo para examen de seleccion multiple con justificacion.</td>
</tr>
<tr>
<td>8-29</td>
<td>Formato de instruccion con registros</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=376" target="_blank">Problemas cap. 8 / PDF p. 376</a></td>
<td>Practica repartir bits entre operacion, direccion y seleccion de registro.</td>
</tr>
<tr>
<td>8-30 y 8-31</td>
<td>Secuencia de microoperaciones</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=376" target="_blank">Problemas cap. 8 / PDF p. 376-377</a></td>
<td>Une memoria, instruccion, PC, MAR/MBR y ejecucion; util para justificar como se lee y ejecuta una instruccion.</td>
</tr>
<tr>
<td>8-32</td>
<td>Instrucciones ADD inmediato y ADD a memoria</td>
<td><a href="/study/arquitectura/libros/arquitectura-de-computadoras-morris-mano.pdf#page=377" target="_blank">Problemas cap. 8 / PDF p. 377</a></td>
<td>Ayuda a diferenciar operando inmediato, direccion de memoria y transferencia necesaria para ejecutar una instruccion.</td>
</tr>
</tbody>
</table>
<p class="small">Nota: el PDF disponible termina en la pagina 547, dentro de la seccion 12-4, por eso no se listan problemas del capitulo 12 aunque la lectura si es muy util.</p>
</div>
</div>
Apendice D: Ejercicios de la presentacion
Ejercicios y ejemplos ubicados en las diapositivas del segundo parcial, con el tipo de respuesta que conviene practicar.
<div class="notice">
<strong>Uso sugerido:</strong> usa esta tabla como puente entre la presentacion y el banco interactivo. Si un ejercicio de diapositivas se parece a uno del banco, intenta primero el del banco con captura y solucion.
</div>
<table>
<thead>
<tr>
<th>Diapositivas</th>
<th>Ejercicio o ejemplo</th>
<th>Tipo de respuesta esperada</th>
</tr>
</thead>
<tbody>
<tr>
<td>7-10</td>
<td>Tiempo promedio de acceso de dos niveles.</td>
<td>Aplicar <code>Ts = T1 + (1-H)T2</code> y explicar por que H debe acercarse a 1.</td>
</tr>
<tr>
<td>14-16</td>
<td>Sistema de tres niveles: cache, memoria principal y disco.</td>
<td>Convertir ms a ns y aplicar <code>Ts = T1 + (1-H1)T2 + (1-H1)(1-H2)T3</code>.</td>
</tr>
<tr>
<td>34-39</td>
<td>Memoria de 32 bloques y cache de 8 lineas.</td>
<td>Calcular linea con modulo, identificar etiqueta y justificar bit de validez/tag.</td>
</tr>
<tr>
<td>43-56</td>
<td>Ejemplo de cache de 64 KB, memoria de 16 MB, bloques de 4 bytes.</td>
<td>Calcular numero de lineas, bloques de memoria, campos <code>s</code>, <code>r</code>, <code>w</code>, etiqueta y bits totales.</td>
</tr>
<tr>
<td>62-65</td>
<td>Direccion de byte 36 con cache directa de 32 bytes y bloque de 4 bytes.</td>
<td>Distinguir direccion de byte contra direccion de bloque; calcular bloque y linea.</td>
</tr>
<tr>
<td>67-70</td>
<td>Tasa de aciertos y tiempo promedio para programa que recorre direcciones.</td>
<td>Simular bloques cargados, contar hits/misses y usar tiempo de acceso.</td>
</tr>
<tr>
<td>91-93</td>
<td>Problema 4.1: cache asociativa por conjuntos, 64 lineas, conjuntos de 4, memoria de 4K bloques, bloque de 128 palabras.</td>
<td>Formato de direccion: etiqueta, conjunto y palabra.</td>
</tr>
<tr>
<td>94-97</td>
<td>Problema 4.2: cache asociativa por conjuntos de dos vias, lineas de 16 bytes, 8 KB, memoria de 64 MB.</td>
<td>Calcular lineas, conjuntos, bits de desplazamiento, conjunto y etiqueta.</td>
</tr>
<tr>
<td>98-108</td>
<td>Problema 4.3: direcciones hexadecimales y formatos directa/asociativa/asociativa por conjuntos.</td>
<td>Separar direccion hexadecimal en campos y presentar etiqueta, linea/conjunto y palabra.</td>
</tr>
<tr>
<td>109-112</td>
<td>Problema 4.4: parametros de los ejemplos directa, asociativa y asociativa por conjuntos.</td>
<td>Calcular longitud de direccion, unidades direccionables, tamano de bloque, bloques, lineas y etiqueta.</td>
</tr>
<tr>
<td>113-117</td>
<td>Problema 4.5: microprocesador de 32 bits, cache de 16 KB, 4 vias, linea de cuatro palabras de 32 bits.</td>
<td>Dibujar organizacion y ubicar la direccion <code>ABCDE8F8</code> en conjunto/offset.</td>
</tr>
<tr>
<td>118-120</td>
<td>Problema 4.6: cache externa de cuatro vias con linea de dos palabras de 16 bits, 4K palabras de 32 bits y direcciones de 24 bits.</td>
<td>Disenar estructura de cache e interpretar campos de direccion.</td>
</tr>
<tr>
<td>122-125</td>
<td>Problema 4.8: memoria principal <code>2^16</code> bytes, bloque de 8 bytes, cache directa de 32 lineas.</td>
<td>Dividir direccion de 16 bits en etiqueta/linea/byte, ubicar direcciones y explicar etiquetas.</td>
</tr>
<tr>
<td>126-128</td>
<td>Problema 4.10: cache asociativa por conjuntos, bloque de cuatro palabras de 16 bits, conjunto de 2, 4096 palabras, memoria de 64K x 32 bits.</td>
<td>Disenar formato de direccion y estructura de cache.</td>
</tr>
<tr>
<td>131-136</td>
<td>Ejemplos LRU con 4 y 8 lineas.</td>
<td>Simular secuencia, marcar hits y determinar donde cae el ultimo bloque.</td>
</tr>
<tr>
<td>180-188</td>
<td>Prestaciones: CPI base, frecuencia de fallos, penalizacion por fallo, cache perfecta y cache multinivel.</td>
<td>Calcular ciclos de parada, CPI efectivo, speedup y efecto de L2.</td>
</tr>
</tbody>
</table>
Comentarios
Comparte una idea, pregunta o aporte sobre este articulo.
Todavia no hay comentarios. Puedes abrir la conversacion.